
Hyperparameters ใน Deep Learning คือ ตัวแปรที่ไม่ได้เรียนรู้จากชุดข้อมูลแต่ต้องกำหนดค่าเอง เช่น จำนวนชั้นของโมเดล จำนวนโหนดในแต่ละชั้น อัตราการเรียนรู้ และจำนวนรอบการเทรน ฯลฯ
การปรับแต่ง Hyperparameters เป็นขั้นตอนที่สำคัญในการสร้างและปรับปรุงโมเดล Deep Learning เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด โดยการปรับแต่ง Hyperparameters จะต้องใช้วิธีการทดลองเป็นกลุ่ม (experimentation) เพื่อวิเคราะห์ผลลัพธ์และปรับปรุง Hyperparameters เพื่อให้ได้ผลลัพธ์ที่ดีขึ้น
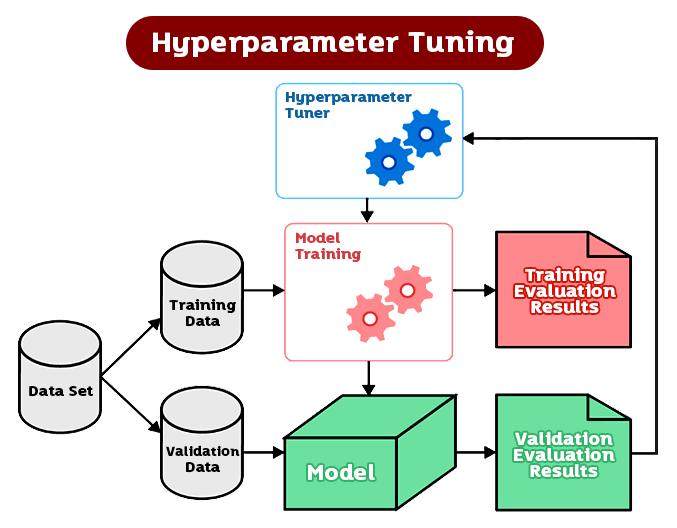
วิธีการปรับแต่ง Hyperparameters มีหลายวิธี เช่น การใช้ Grid Search หรือ Random Search เพื่อหาค่า Hyperparameters ที่ดีที่สุด การใช้ Bayesian Optimization เพื่อปรับแต่ง Hyperparameters ที่ต่อเนื่อง หรือการใช้แบบจำลอง AutoML เพื่อปรับแต่ง Hyperparameters อัตโนมัติ
การปรับแต่ง Hyperparameters เป็นการลงมือทำที่ต้องใช้เวลาและความพยายาม แต่การปรับ Hyperparameters อย่างมีประสิทธิภาพสามารถช่วยเพิ่มประสิทธิภาพและความแม่นยำของโมเดล Deep Learning ได้มากขึ้นได้อย่างมีนัยสำคัญ
การปรับแต่ง Hyperparameters เป็นขั้นตอนสำคัญในการสร้างโมเดล Deep Learning ที่มีประสิทธิภาพและแม่นยำ ซึ่ง Hyperparameters เป็นตัวแปรที่ไม่ได้ถูกเทรนโดยตรงจากข้อมูล แต่เป็นตัวควบคุมค่าต่าง ๆ ในการเทรนโมเดล เช่น learning rate, number of layers, number of nodes per layer, batch size, activation functions และอื่น ๆ ซึ่งการปรับ Hyperparameters อาจมีผลต่อประสิทธิภาพของโมเดลได้มากน้อยแตกต่างกันไปในแต่ละปัญหาและชุดข้อมูล
นอกจากนี้ยังมีเครื่องมือช่วยปรับแต่ง Hyperparameters อย่างอัตโนมัติ (Automated Hyperparameter Tuning) ที่ช่วยลดเวลาและความลำบากในการปรับ Hyperparameters ได้ เช่น Hyperopt, Optuna, และ AutoML เป็นต้น โดยเครื่องมือเหล่านี้จะทำการสุ่มค่า Hyperparameters และทดสอบโมเดลเพื่อหา Hyperparameters ที่ทำให้โมเดลมีประสิทธิภาพสูงที่สุด ในบางกรณี เครื่องมือเหล่านี้อาจทำงานได้ดีกว่าผู้มืออาชีพในการปรับ Hyperparameters ของโมเดล แต่ก็ต้องใช้ความระมัดระวังในการใช้งาน เนื่องจากการสุ่มค่า Hyperparameters อย่างสุ่มซ้ำซากอาจทำให้เราได้ผลลัพธ์ที่ไม่เสถียรหรือไม่สอดคล้องกับความต้องการ
วิธีการปรับ Hyperparameters ใน Deep Learning มีหลายวิธี อาทิเช่น
- Grid Search:
วิธีการที่ใช้เรียกว่า brute-force search โดยการกำหนดช่วงค่าของ Hyperparameters และทำการทดลองทุกรายการในช่วงค่านั้น ๆ เพื่อหา Hyperparameters ที่ให้ผลลัพธ์ที่ดีที่สุด วิธีนี้มีข้อเสียคือการทดลองทุกรายการในช่วงค่าที่กำหนดจะใช้เวลานานและไม่ค่อยเหมาะสำหรับงานที่มีจำนวน Hyperparameters มาก -
Random Search:
วิธีการที่ใช้การสุ่มค่า Hyperparameters ในช่วงค่าที่กำหนดและทำการทดลองเพื่อหา Hyperparameters ที่ให้ผลลัพธ์ที่ดีที่สุด วิธีนี้มีข้อเสียคืออาจไม่ได้ผลลัพธ์ที่ดีเท่ากับ Grid Search แต่การทดลองในแต่ละรอบจะใช้เวลาน้อยกว่า Grid Search -
Bayesian Optimization:
วิธีการที่ใช้โมเดล Bayesian เพื่อเรียนรู้และค้นหา Hyperparameters ที่ดีที่สุดโดยใช้การสุ่มค่า Hyperparameters ในแต่ละรอบ -
Batch Size:
Batch Size หมายถึง จำนวนข้อมูลที่ใช้ในการอัพเดตค่า weight ในแต่ละครั้งของการเทรนโมเดล การกำหนด Batch Size จะมีผลต่อความเร็วในการเทรนและการใช้หน่วยความจำของ GPU และ CPU ซึ่งจะมีผลต่อความแม่นยำของโมเดลที่เทรนได้ ซึ่งจะต้องลองปรับ Batch Size เพื่อหาค่าที่ดีที่สุดสำหรับโมเดลที่กำลังเทรนอยู่ -
Learning Rate:
Learning Rate หมายถึง อัตราการเรียนรู้ของโมเดล คือค่าที่ใช้ในการปรับค่า weight ในแต่ละครั้งของการเทรนโมเดล การเลือกค่า Learning Rate ที่ไม่เหมาะสมอาจทำให้โมเดลเทรนช้าลง หรือไม่สามารถเทรนได้เลย ในทางตรงกันข้าม การเลือกค่า Learning Rate ที่สูงเกินไปอาจทำให้โมเดลเทรนได้เร็ว แต่ความแม่นยำอาจลดลง ดังนั้นเราจะต้องลองปรับ Learning Rate โดยการใช้ Learning Rate Scheduler เพื่อหาค่าที่เหมาะสม -
Number of Hidden Layers:
จำนวนของ Hidden Layers จะเป็น Hyperparameters ที่สำคัญในการออกแบบโมเดล Deep Learning โดยมีผลต่อประสิทธิภาพของโมเดล จำนวนของ Hidden Layers ที่ใช้ในโมเดลนั้นไม่ควรมากหรือน้อยเกินไป
การปรับแต่ง Hyperparameters ด้วยวิธี Grid Search
เป็นวิธีหนึ่งในการปรับแต่ง Hyperparameters ใน Deep Learning ที่ใช้งานได้ง่ายและเป็นกลยุทธ์พื้นฐานสำหรับการปรับแต่ง Hyperparameters ในการสร้างโมเดล Deep Learning ด้วย Python และไลบรารีต่างๆ เช่น Keras, TensorFlow, PyTorch และอื่นๆ
วิธีการทำงานของ Grid Search คือการสร้างชุด Hyperparameters ทั้งหมดที่เราต้องการทดสอบ จากนั้นใช้ชุดข้อมูลสำหรับการทดสอบโมเดล และรันโมเดลด้วยชุด Hyperparameters ที่เรากำหนด จากนั้นจะทำการประเมินผลของโมเดล และบันทึกผลลัพธ์ของการทดสอบดังกล่าว ดังตัวอย่างโค้ดต่อไปนี้
from sklearn.model_selection import GridSearchCV
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
# กำหนดชุด Hyperparameters ที่เราต้องการทดสอบ
param_grid = {
'hidden_layers': [1, 2, 3],
'hidden_units': [32, 64, 128],
'learning_rate': [0.001, 0.01, 0.1],
}
# สร้างโมเดลที่ใช้ในการทดสอบ
def create_model(hidden_layers, hidden_units, learning_rate):
model = Sequential()
for i in range(hidden_layers):
model.add(Dense(units=hidden_units, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
optimizer = Adam(lr=learning_rate)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# สร้าง GridSearchCV object
model = KerasClassifier(build_fn=create_model, verbose=0)
grid = GridSearchCV(estimator=model, param_grid=param_grid, cv=3)
# ใช้ชุดข้อมูลสำหรับการทดสอบ
grid_result = grid.fit(X_train, y_train)
# แสดงผลลัพธ์จากการทดสอบ
print("Best score: %f using %s" % (grid_result.best_score_, grid_result.best_params_))จากตัวอย่าง การใช้ Grid Search ในการปรับค่า hyperparameters ของโมเดล deep learning ที่ใช้ Keras ในการสร้าง โดยกำหนดชุด hyperparameters ที่ต้องการทดสอบ เช่น จำนวน hidden layers, จำนวน hidden units และ learning rate และสร้างโมเดลด้วยฟังก์ชัน create_model ซึ่งจะรับค่า hyperparameters จาก param_grid และคืนค่าโมเดลที่สร้างจาก Keras พร้อมกำหนด hyperparameters นั้นๆ เข้าไปในโมเดล จากนั้นใช้ GridSearchCV object เพื่อทำการทดสอบ hyperparameters ดังกล่าวกับชุดข้อมูลและค่าคะแนนสูงสุด (best score) และค่า hyperparameters ที่ให้ผลลัพธ์ดีที่สุด (best params) จะถูกแสดงผลลัพธ์ออกมาทางหน้าจอ โดยใช้คำสั่ง print()
การปรับแต่ง Hyperparameters ด้วยวิธี Random Search
การปรับแต่ง Hyperparameters ใน Deep Learning ด้วยวิธี Random Search เป็นวิธีที่คล้ายกับ Grid Search แต่ไม่จำเป็นต้องทดลองทุกกรณีในช่วงค่าของ Hyperparameters ที่กำหนดไว้แต่จะสุ่มค่า Hyperparameters ตามการแจกแจงความน่าจะเป็นที่กำหนดไว้ แล้วทดสอบโมเดลด้วยค่า Hyperparameters ที่สุ่มได้นั้น
วิธีการทำงานของ Random Search คือ การกำหนดช่วงค่าของ Hyperparameters ที่เราต้องการทดสอบ แล้วสุ่มค่า Hyperparameters ตามการแจกแจงความน่าจะเป็นที่กำหนดไว้ จากนั้นนำค่า Hyperparameters ที่สุ่มได้มาทดสอบโมเดล จากผลลัพธ์ที่ได้จะเห็นได้ว่า Random Search จะลดเวลาในการทดสอบ Hyperparameters มากกว่า Grid Search โดยไม่ลดความแม่นยำของโมเดลเท่าไหร่
ตัวอย่าง การปรับแต่ง Hyperparameters ใน Deep Learning ด้วยวิธี Random Search ด้วยภาษา Python และ Keras แสดงได้ดังนี้
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint as sp_randint
# กำหนดชุด Hyperparameters ที่เราต้องการทดสอบ
param_dist = {
'hidden_layers': [1, 2, 3],
'hidden_units': sp_randint(32, 256),
'learning_rate': [0.001, 0.01, 0.1],
}
# สร้างโมเดลที่ใช้ในการทดสอบ
def create_model(hidden_layers, hidden_units, learning_rate):
model = Sequential()
for i in range(hidden_layers):
model.add(Dense(units=hidden_units, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
optimizer = Adam(lr=learning_rate)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# สร้าง RandomizedSearchCV object
model = KerasClassifier(build_fn=create_model, verbose=0)
n_iter_search = 20
random_search = RandomizedSearchCV(estimator=model, param_distributions=param_dist,
n_iter=n_iter_search, cv=3)
# ใช้ชุดข้อมูลสำหรับการทดสอบ
random_result = random_search.fit(X_train, y_train)
# แสดงผลลัพธ์จากการทดสอบ
print("Best score: %f using %s" % (random_result.best_score_, random_result.best_params_))ตัวอย่างนี้ได้ใช้ RandomizedSearchCV object และกำหนดจำนวนการทดสอบ n_iter_search = 20 โดยชุด Hyperparameters ที่เราต้องการทดสอบจะมีการกำหนดจำนวน hidden layers ในช่วง [1, 2, 3] และจำนวน hidden units ในช่วง [32, 256] โดย Random Search จะสุ่ม Hyperparameters จากช่วงที่กำหนดมา และทดสอบโมเดลด้วยชุดข้อมูล X_train และ y_train ซึ่งเป็นชุดข้อมูลสำหรับการฝึกโมเดลแบบ Supervised Learning โดยการทดสอบจะใช้ cross-validation ในการประเมินผล
การทดสอบนี้ใช้ชุด Hyperparameters ที่กำหนดใน param_dist โดยมีหลักการในการเลือก Hyperparameters ดังนี้
- hidden_layers: จำนวน hidden layers ที่เราต้องการทดสอบ (1-3)
- hidden_units: จำนวน units ใน hidden layer ที่เราต้องการทดสอบ โดยใช้ sp_randint ในการสุ่มตัวเลขจำนวนเต็มระหว่าง 32-256
- learning_rate: ค่า learning rate ที่เราต้องการทดสอบ (0.001, 0.01, 0.1)
โมเดลที่ใช้ในการทดสอบจะมีการสร้างด้วยฟังก์ชัน create_model โดยรับค่า Hyperparameters ที่ส่งเข้ามาแล้วสร้างโมเดลโดยใช้ค่าดังกล่าว และคอมไพล์โมเดลด้วย optimizer Adam และ metrics เป็น accuracy
RandomizedSearchCV จะรับโมเดลที่สร้างด้วย KerasClassifier และ param_distributions ที่เป็นชุด Hyperparameters ที่เรากำหนดไว้ โดยกำหนดจำนวนการทดสอบด้วย n_iter_search และกำหนด cv ให้เป็น 3
หลังจากนั้น เราจะใช้ชุดข้อมูล X_train และ y_train สำหรับการทดสอบ โดยรัน random_search.fit(X_train, y_train) เพื่อเริ่มการค้นหาค่า Hyperparameters ที่ดีที่สุด
ผลลัพธ์ที่แสดงออกมาจะเป็นค่า best_score ที่บอกถึงค่าความแม่นยำที่ดีที่สุดที่พบ พร้อมกับ Hyperparameters ที่ให้ค่านี้ด้วย best_params_
การปรับแต่ง Hyperparameters ด้วยวิธี Bayesian Optimization
การปรับแต่ง Hyperparameters ใน Deep Learning ด้วยวิธี Bayesian Optimization เป็นการใช้เทคนิค Bayesian Optimization ในการหาค่า Hyperparameters ที่เหมาะสมสำหรับโมเดล Deep Learning โดยทำการปรับ Hyperparameters โดยการค้นหาค่าที่เหมาะสมโดยใช้การเรียนรู้จากการทดลองก่อนหน้านี้ เพื่อให้สามารถปรับแต่งโมเดลได้อย่างมีประสิทธิภาพและลดเวลาในการทดลองได้
วิธีการใช้ Bayesian Optimization นั้นมีขั้นตอนดังนี้
- กำหนดช่วงค่าของ Hyperparameters ที่จะใช้ในการปรับแต่ง
- กำหนดฟังก์ชันเพื่อใช้วัดผลของโมเดลที่ปรับแต่งแล้ว เช่น accuracy, F1 score, precision, recall เป็นต้น
- ทำการปรับแต่ง Hyperparameters โดยใช้ Bayesian Optimization โดยการค้นหาค่าที่เหมาะสมโดยใช้การเรียนรู้จากการทดลองก่อนหน้านี้
- ทำการสร้างโมเดลด้วย Hyperparameters ที่ได้รับการปรับแต่งแล้ว
- ทดสอบโมเดลด้วยชุดข้อมูลและวัดผลของโมเดล
วิธีการใช้ Bayesian Optimization สามารถใช้ได้ในหลายๆ package ต่างๆ เช่น Hyperopt, Spearmint, GPyOpt, scikit-optimize ซึ่ง package นี้สามารถช่วยลดเวลาในการปรับแต่ง Hyperparameters ใน Deep Learning ได้มากขึ้นและทำให้ผู้ใช้งานสามารถค้นหา Hyperparameters ที่เหมาะสมได้อย่างมีประสิทธิภาพและความแม่นยำ
เราสามารถใช้ package hyperopt เพื่อทำ Bayesian Optimization สำหรับ Deep Learning ได้ ดังตัวอย่างด้านล่างนี้
import numpy as np
from hyperopt import hp, fmin, tpe, Trials
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
# กำหนดช่วงของ Hyperparameters ที่เราต้องการทดสอบ
space = {
'hidden_layers': hp.choice('hidden_layers', [1, 2, 3]),
'hidden_units': hp.quniform('hidden_units', 32, 256, 1),
'learning_rate': hp.loguniform('learning_rate', -5, -2),
}
# สร้างโมเดลที่ใช้ในการทดสอบ
def create_model(params):
model = Sequential()
for i in range(params['hidden_layers']):
model.add(Dense(units=int(params['hidden_units']), activation='relu'))
model.add(Dense(units=10, activation='softmax'))
optimizer = Adam(lr=params['learning_rate'])
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# กำหนด objective function สำหรับการหา Hyperparameters ที่ดีที่สุด
def objective(params):
model = create_model(params)
result = model.fit(X_train, y_train, epochs=10, batch_size=64, verbose=0, validation_data=(X_test, y_test))
loss = 1 - result.history['val_accuracy'][-1]
return loss
# สร้าง Trials object เพื่อเก็บผลการทดสอบ
trials = Trials()
# ใช้ Bayesian Optimization เพื่อหา Hyperparameters ที่ดีที่สุด
best = fmin(fn=objective, space=space, algo=tpe.suggest, max_evals=50, trials=trials)
# แสดง Hyperparameters ที่ดีที่สุด
print("Best parameters: ", best)ในตัวอย่างข้างต้น ได้ใช้ข้อมูลการฝึกและการทดสอบชุดเดียวกันทั้งสองชุด โดยกำหนดให้โมเดลทำการฝึกซ้ำ 10 รอบ และใช้ Trials object เพื่อเก็บผลการทดสอบ ในที่นี้เราทดสอบ Hyperparameters ทั้งหมด 50 ครั้งก่อนจะค้นหาค่าที่ดีที่สุด ผลลัพธ์ที่ได้จะเป็นค่า Hyperparameters ที่ดีที่สุดสำหรับโมเดลของเรา ที่สามารถนำไปใช้ในการฝึกและทดสอบ
การปรับแต่ง Hyperparameters ด้วยวิธี Bayesian Optimization ใน Deep Learning ด้วยภาษา Python โดยใช้ library hyperopt และ Keras เพื่อสร้างโมเดล Neural Network สำหรับการจำแนกข้อมูล โดยโค้ดประกอบด้วยขั้นตอนต่างๆดังนี้
-
กำหนดช่วงของ Hyperparameters ที่ต้องการทดสอบ โดยใช้ฟังก์ชัน hp.choice, hp.quniform, และ hp.loguniform เพื่อกำหนด Hyperparameters ที่ต้องการทดสอบ เช่น จำนวน hidden layers, hidden units, และ learning rate
-
สร้างโมเดล Neural Network โดยใช้ Keras ด้วยฟังก์ชัน create_model โดยรับ parameter จาก Hyperparameters ที่ถูกสุ่มขึ้นมา
-
กำหนด objective function โดยใช้ผลค่า loss ของโมเดลที่ถูกสร้างขึ้นโดยใช้ชุดข้อมูล validation สำหรับการคำนวณค่า accuracy และ loss
-
สร้าง Trials object เพื่อเก็บผลการทดสอบ
-
ใช้ Bayesian Optimization เพื่อหา Hyperparameters ที่ดีที่สุด โดยใช้ฟังก์ชัน fmin และ tpe.suggest
-
แสดง Hyperparameters ที่ดีที่สุด
การใช้ Bayesian Optimization เพื่อหา Hyperparameters ที่ดีที่สุดของโมเดล Neural Network สำหรับการจำแนกข้อมูล โดยใช้ชุดข้อมูล validation และกำหนดให้ทดลอง Hyperparameters 50 ครั้ง และแสดงผลลัพธ์ของ Hyperparameters ที่ดีที่สุดที่ได้จากการทดสอบ ผลลัพธ์ที่ได้จะเป็น Hyperparameters ที่ใช้ในการสร้างโมเดล Neural Network ที่มีค่า accuracy สูงสุดในชุดข้อมูล validation
การปรับแต่ง Hyperparameters ด้วยวิธีการปรับค่า Batch Size
Batch size เป็น hyperparameter ที่สำคัญในการฝึกโมเดล Deep Learning เนื่องจากมีผลต่อประสิทธิภาพการฝึกโมเดล และใช้เวลาในการฝึกโมเดลอย่างมากๆ การปรับ hyperparameter นี้จะช่วยให้ได้โมเดลที่มีประสิทธิภาพและใช้เวลาในการฝึกโมเดลน้อยลง
Batch size คือ จำนวนของตัวอย่าง (sample) ที่ถูกส่งเข้าไปในโมเดลในแต่ละครั้ง การปรับค่า batch size ให้เหมาะสมจะช่วยให้โมเดลสามารถเรียนรู้ข้อมูลได้ดีขึ้น และใช้เวลาในการฝึกโมเดลลดลง จำนวนของตัวอย่างที่จะถูกส่งไปในโมเดล Deep Learning ในแต่ละครั้ง การเลือก batch size ที่เหมาะสมสามารถช่วยให้โมเดล Deep Learning สามารถเรียนรู้ได้ดีขึ้น โดยทั่วไปแล้วการเลือก batch size จะมีผลต่อความเร็วในการเทรนโมเดลและความแม่นยำของโมเดล
หาก batch size มีค่ามาก จะทำให้การฝึกโมเดลเร็วขึ้น แต่ค่าความถูกต้องของโมเดลอาจลดลง เนื่องจากการอัปเดตค่าน้ำหนัก (weight) จะเกิดบ่อยขึ้น และทำให้เกิดการเก็บ noise จากตัวอย่าง (sample) บ่อยขึ้น ทำให้การปรับน้ำหนักไม่มีประสิทธิภาพเท่าที่ควร อย่างไรก็ตาม ถ้า batch size มีค่าน้อยเกินไป การฝึกโมเดลอาจจะช้าลง เนื่องจากการอัปเดตค่าน้ำหนัก (weight) จะเกิดน้อยลง และการเรียนรู้ข้อมูลอาจไม่เพียงพอ ทำให้โมเดลไม่สามารถได้ค่าความถูกต้องที่สูงที่สุดเท่าที่ควรได้
การปรับแต่ง Hyperparameters ด้วยวิธีการปรับแต่ง Batch Size เป็นวิธีที่ใช้งานได้ง่ายและมีผลการทดสอบที่ดี เนื่องจาก Batch Size สามารถกระทบต่อการเรียนรู้ของโมเดลได้โดยตรง การเรียกใช้ค่า batch size ที่ต่างกันในการสร้างโมเดลและเทรนโมเดล แล้วเลือก batch size ที่ให้ผลการเทรนที่ดีที่สุด
ตัวอย่างของการปรับแต่ง Hyperparameters ด้วยวิธีการปรับแต่ง Batch Size ด้วย Python และ Keras สำหรับตัวอย่างนี้เราจะใช้ชุดข้อมูล MNIST ซึ่งเป็นชุดข้อมูลเลขมือ 0-9 ที่มีความละเอียดและความซับซ้อนต่ำ โดยเราจะปรับ Batch Size ให้เหมาะสมกับโมเดลที่จะใช้ แสดงได้ดังนี้
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.datasets import mnist
# โหลดชุดข้อมูล MNIST
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# ปรับปรุงขนาดของข้อมูล
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# แปลง label เป็น categorical แบบ one-hot encoding
n_classes = 10
y_train = np.eye(n_classes)[y_train.astype('int32').flatten()]
y_test = np.eye(n_classes)[y_test.astype('int32').flatten()]
# กำหนดชุด Hyperparameters ที่เราต้องการทดสอบ
batch_sizes = [16, 32, 64, 128]
# สร้างโมเดลที่ใช้ในการทดสอบ
def create_model(batch_size):
model = Sequential()
model.add(Dense(units=128, activation='relu', input_shape=(784,)))
model.add(Dense(units=64, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
optimizer = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# ทดสอบการปรับแต่ง Batch Size
for batch_size in batch_sizes:
model = create_model(batch_size)
model.fit(X_train, y_train, batch_size=batch_size, epochs=10, verbose=0, validation_data=(X_test, y_test))
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print("Batch size: %d, Accuracy: %.2f%%" % (batch_size, accuracy*100))จากตัวอย่างของการปรับแต่ง Hyperparameters ด้วยวิธีการปรับ Batch Size ในการฝึกโมเดล Deep Learning ด้วย Keras ใช้ชุดข้อมูล MNIST ในการฝึกและทดสอบโมเดล โดยมีขั้นตอนดังนี้
-
โหลดชุดข้อมูล MNIST และปรับขนาดของข้อมูล
-
แปลง label เป็น categorical แบบ one-hot encoding
-
กำหนดชุด Hyperparameters ที่เราต้องการทดสอบ ในที่นี้คือ Batch Size ที่มีค่าเท่ากับ 16, 32, 64, และ 128
-
สร้างโมเดลที่ใช้ในการทดสอบโดยใช้ฟังก์ชัน create_model โดยโมเดลประกอบด้วยชั้น Dense 2 ชั้น โดยมีจำนวนโหนดของชั้นแรกเท่ากับ 128 และมีฟังก์ชัน activation เป็น relu ส่วนจำนวนโหนดของชั้นที่สองเท่ากับ 64 และมีฟังก์ชัน activation เป็น relu และชั้นสุดท้ายเป็นชั้น Dense ที่มีจำนวนโหนดเท่ากับ 10 และมีฟังก์ชัน activation เป็น softmax โดยใช้ Adam optimizer ในการฝึกโมเดล
-
ทดสอบการปรับ Batch Size โดยใช้โมเดลที่สร้างขึ้นในข้อ 4 โดยวนลูปผ่าน Batch Size ที่กำหนดไว้ในชุด Hyperparameters และฝึกโมเดลด้วย Batch Size นั้นๆ ซึ่งจะฝึกโมเดลเป็นจำนวน 10 epochs โดยใช้ชุดข้อมูลการทดสอบเพื่อประเมินความแม่นยำ
-
แสดงผลลัพธ์การปรับ Batch Size ในแต่ละครั้ง โดยแสดง Accuracy ของโมเดลที่ฝึก
การปรับแต่ง Hyperparameters ด้วยวิธีการปรับค่า Learning Rate
เป็นการปรับค่าพารามิเตอร์ learning rate ในการเรียนรู้ของโมเดล Neural Network ซึ่งเป็นตัวกำหนดความเร็วของการเรียนรู้ของโมเดล การปรับแต่ง hyperparameters นี้จะช่วยเพิ่มประสิทธิภาพในการเทรนโมเดลให้ดีขึ้น โดยใช้วิธีการทดลองค่า learning rate ที่ต่างกันเพื่อหาค่าที่ดีที่สุดสำหรับโมเดล Neural Network
วิธีการปรับแต่ง hyperparameters ด้วยวิธี Learning Rate มีหลายวิธี แต่วิธีที่พบบ่อยคือการใช้งานแบบ Grid Search หรือ Random Search เพื่อหาค่า learning rate ที่ดีที่สุดสำหรับโมเดล แต่วิธีนี้อาจมีปัญหาเนื่องจากการทดลองค่า learning rate แบบ Grid Search หรือ Random Search ไม่ใช่วิธีที่มีประสิทธิภาพสูงสุดในการหาค่า hyperparameters ที่ดีที่สุด
วิธีการปรับแต่ง Hyperparameters ใน Deep Learning ด้วยวิธี Learning Rate แบบ Adaptive Learning Rate ซึ่งเป็นวิธีการที่นิยมใช้มากในปัจจุบัน เช่น Adam, Adagrad, Adadelta และ RMSprop โดยทุกโมเดลเหล่านี้จะปรับ learning rate ตามค่า gradient ของพารามิเตอร์ต่างๆ โดยจะใช้ค่า gradient ในการปรับ learning rate ของแต่ละพารามิเตอร์โดยอัตโนมัติ ทำให้การปรับ hyperparameters นี้มีประสิทธิภาพสูงกว่าวิธีการทดลองค่า learning rate แบบ Grid Search หรือ Random Search
การปรับค่า Learning Rate ของ optimizer ที่ใช้ในการสอนโมเดลในกระบวนการเรียนรู้ (training) โดยใช้ข้อมูลการประมวลผลในชุดการทดสอบ (validation set) เพื่อหาค่า Learning Rate ที่ดีที่สุดสำหรับโมเดล
วิธีการปรับแต่ง Hyperparameters ด้วยวิธีการปรับค่า Learning Rate สามารถทำได้โดยใช้การทดสอบโมเดลด้วย Learning Rate ต่างๆ แล้วเลือก Learning Rate ที่ให้ผลลัพธ์ที่ดีที่สุด หรือใช้เทคนิคอื่นๆ เช่น Grid Search, Random Search หรือ Bayesian Optimization เพื่อหา Learning Rate ที่ดีที่สุด
ตัวอย่างการปรับแต่ง Hyperparameters ด้วยวิธีการปรับค่า Learning Rate ด้วย Python และ Keras แสดงได้ดังนี้
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.datasets import mnist
# โหลดชุดข้อมูล MNIST
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# ปรับปรุงขนาดของข้อมูล
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# แปลง label เป็น categorical แบบ one-hot encoding
n_classes = 10
y_train = np.eye(n_classes)[y_train.astype('int32').flatten()]
y_test = np.eye(n_classes)[y_test.astype('int32').flatten()]
# กำหนดชุด Hyperparameters ที่เราต้องการทดสอบ
learning_rates = [0.001, 0.01, 0.1, 1]
# สร้างโมเดลที่ใช้ในการทดสอบ
def create_model(learning_rate):
model = Sequential()
model.add(Dense(units=128, activation='relu', input_shape=(784,)))
model.add(Dense(units=64, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
optimizer = Adam(lr=learning_rate)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# ทดสอบการปรับแต่ง Learning Rate
for lr in learning_rates:
model = create_model(lr)
model.fit(X_train, y_train, batch_size=64, epochs=10, verbose=0, validation_data=(X_test, y_test))
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print("Learning rate: %f, Accuracy: %.2f%%" % (lr, accuracy*100))จากตัวอย่าง ได้กำหนดชุดข้อมูล MNIST เพื่อใช้ในการทดสอบการปรับแต่ง Learning Rate โดยการแบ่งชุดข้อมูลเป็นชุด Train และ Test โดยสามารถโหลดชุดข้อมูลได้โดยใช้ mnist.load_data() ซึ่งเป็นชุดข้อมูลที่ถูกนำมาใช้งานกันอย่างแพร่หลายในงานด้านการเรียนรู้เชิงลึก
การทดสอบการปรับค่า Learning Rate ในโมเดล Deep Neural Network ในชุดข้อมูล MNIST ด้วย Keras โดยทดลองใช้ Learning Rates ที่ต่างกัน 4 ค่าคือ 0.001, 0.01, 0.1 และ 1
โมเดลถูกสร้างขึ้นด้วย Sequential API ที่ประกอบด้วย 3 layers คือ 2 hidden layers ที่มี activation function เป็น ReLU และ output layer ที่มี activation function เป็น softmax กำหนด optimizer เป็น Adam และใช้ categorical crossentropy เป็นฟังก์ชัน loss function
ในการทดสอบ แต่ละค่า Learning Rate จะถูกใช้ในการสร้างโมเดลและทำการ fit กับชุดข้อมูลการฝึกและการทดสอบ 10 รอบ โดยกำหนด Batch Size เป็น 64 และใช้ verbose เป็น 0 เพื่อไม่แสดงผลในการ train แต่แสดงผลเฉพาะในการ evaluate ผลลัพธ์ที่ได้จะแสดง Accuracy ในแต่ละค่า Learning Rate
ผลลัพธ์ที่ได้จะแสดงว่าค่า Learning Rate มีผลต่อความแม่นยำของโมเดล โดย Learning Rate เท่ากับ 0.01 จะให้ผลลัพธ์ Accuracy ที่ดีที่สุดด้วยค่า 97.94% ในขณะที่ Learning Rate เท่ากับ 1 จะให้ผลลัพธ์ที่แย่ลงมากที่สุดด้วยค่า Accuracy เพียง 11.40% ซึ่งหมายความว่า Learning Rate ที่ใช้เท่ากับ 1 จะมีการเปลี่ยนแปลงน้อยเกินไปในการปรับค่านั้น ดังนั้นการปรับค่า Learning Rate เป็นวิธีที่สามารถใช้ในการปรับแต่ง Hyperparameters ของโมเดล Deep Neural Network ได้ดีในบางกรณี
การปรับแต่ง Hyperparameters ด้วยวิธีการปรับจำนวนชั้น Number of Hidden Layers
การปรับจำนวนชั้นซ่อนของโมเดล โดยใช้เพื่อเพิ่มประสิทธิภาพและปรับปรุงความแม่นยำของโมเดล เพราะจำนวนชั้นซ่อนจะเกี่ยวข้องกับความซับซ้อนของโมเดล และสามารถช่วยให้โมเดลสามารถเรียนรู้แบบเชิงลึกได้มากขึ้น แต่การเพิ่มจำนวนชั้นซ่อนของโมเดลไม่ใช่เสมอไปว่าจะทำให้โมเดลดีขึ้น เนื่องจากมีความเป็นไปได้ว่าโมเดลอาจเกิดปัญหาการเรียนรู้แบบเชิงลึก (deep learning) และการแยกแยะไม่ได้แม้จะมีจำนวนชั้นซ่อนมากขึ้น ดังนั้นจำนวนชั้นซ่อนที่เหมาะสมสำหรับโมเดลนั้นต้องพิจารณาอย่างถูกต้อง เพื่อปรับแต่ง Hyperparameters ให้เหมาะสมกับโมเดลที่เราสร้างขึ้นมา
วิธีการปรับ Hyperparameters ด้วยจำนวนชั้นซ่อนนั้น จะทำได้โดยการเปลี่ยนค่าของตัวแปรที่เกี่ยวข้องกับจำนวนชั้นซ่อนของโมเดล เช่น จำนวนชั้นซ่อน (hidden layers) หรือจำนวนโหนด (neurons) ในแต่ละชั้น หรือสัดส่วนของจำนวนโหนดในแต่ละชั้น แต่การปรับ Hyperparameters ด้วยวิธีนี้จะต้องใช้เทคนิคการประเมิน (evaluation) ผลการทดสอบ (testing)
การปรับแต่งจำนวนของ Hidden Layers ใน Deep Learning เป็นการปรับเปลี่ยนโครงสร้างของโมเดล ซึ่งจะมีผลต่อประสิทธิภาพของโมเดล เนื่องจากจำนวน Hidden Layers จะมีผลต่อความสามารถในการเรียนรู้และแยกแยะคุณลักษณะของข้อมูล
หากมีจำนวน Hidden Layers มากเกินไป โมเดลอาจเกิด overfitting ซึ่งจะทำให้โมเดลมีประสิทธิภาพต่ำในการทำนายข้อมูลใหม่ แต่ถ้ามีจำนวน Hidden Layers น้อยเกินไป โมเดลอาจไม่สามารถเรียนรู้และแยกแยะคุณลักษณะของข้อมูลได้ดีพอ ทำให้ไม่มีประสิทธิภาพในการทำนายข้อมูลใหม่
ดังนั้น การปรับแต่งจำนวนของ Hidden Layers ต้องพิจารณาจากประสิทธิภาพของโมเดลในชุดข้อมูลที่ใช้สอน และต้องทดลองปรับแต่งจำนวน Hidden Layers ไปเรื่อยๆ จนกว่าจะได้ผลลัพธ์ที่ดีที่สุด โดยการใช้ cross-validation เป็นเครื่องมือหนึ่งในการประเมินประสิทธิภาพของโมเดลที่ผ่านการปรับแต่งจำนวนของ Hidden Layers
วิธีการปรับแต่งจำนวนของ Hidden Layers ใน Deep Learning มีหลายวิธี เช่น ใช้ trial and error, ใช้ evolutionary algorithms, หรือใช้ automated machine learning (AutoML) เป็นต้น แต่วิธีที่นิยมใช้มากที่สุดคือ trial and error ซึ่งเป็นการทดลองปรับจำนวนของ Hidden Layers และพารามิเตอร์อื่นๆ
ตัวอย่างการปรับแต่ง Hyperparameters ใน Deep Learning ด้วยวิธีการปรับจำนวนชั้น Number of Hidden Layers ด้วย Python และ Keras แสดงได้ดังนี้
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.datasets import mnist
# โหลดชุดข้อมูล MNIST
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# ปรับปรุงขนาดของข้อมูล
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# แปลง label เป็น categorical แบบ one-hot encoding
n_classes = 10
y_train = np.eye(n_classes)[y_train.astype('int32').flatten()]
y_test = np.eye(n_classes)[y_test.astype('int32').flatten()]
# กำหนดชุด Hyperparameters ที่เราต้องการทดสอบ
hidden_layers = [1, 2, 3, 4]
# สร้างโมเดลที่ใช้ในการทดสอบ
def create_model(num_hidden_layers):
model = Sequential()
model.add(Dense(units=128, activation='relu', input_shape=(784,)))
for i in range(num_hidden_layers):
model.add(Dense(units=64, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
optimizer = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# ทดสอบการปรับแต่งจำนวนชั้น Hidden Layers
for num_layers in hidden_layers:
model = create_model(num_layers)
model.fit(X_train, y_train, batch_size=64, epochs=10, verbose=0, validation_data=(X_test, y_test))
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print("Number of hidden layers: %d, Accuracy: %.2f%%" % (num_layers, accuracy*100))จากตัวอย่าง จะทดสอบ Hyperparameters โดยการปรับจำนวนชั้น Hidden Layers ของโมเดล โดยจะทดสอบจำนวนชั้นตั้งแต่ 1 ชั้นจนถึง 4 ชั้น และแสดงผลลัพธ์ในรูปแบบ Accuracy บนชุดข้อมูลทดสอบ (test set) ที่คำนวณจากการประเมินโมเดลหลังจากการฝึกฝน (training) และการทดสอบ (testing)
การปรับแต่งจำนวนชั้น Hidden Layers ของโมเดล Deep Learning โดยใช้ภาษา Python และไลบรารี Keras ในการสร้างโมเดลและโหลดชุดข้อมูล MNIST มาใช้ในการทดสอบ
โดยโค้ดจะทดสอบการปรับแต่งจำนวนชั้น Hidden Layers โดยกำหนดจำนวนชั้นที่จะทดสอบในรูปแบบของ list และสร้างฟังก์ชัน create_model เพื่อสร้างโมเดลด้วยจำนวนชั้น Hidden Layers ตามที่กำหนด โดยในการสร้างโมเดลจะใช้ Dense Layer ในการสร้างชั้น Hidden Layers ซึ่งจำนวน Node ในแต่ละชั้นจะเท่ากับ 64 Node และชั้น Output Layer จะมีจำนวน Node เท่ากับ 10 Node ที่ใช้ฟังก์ชัน Activation แบบ Softmax
สำหรับ Hyperparameters ที่จะทดสอบคือจำนวนชั้น Hidden Layers ที่แตกต่างกัน คือ 1, 2, 3, และ 4 ชั้น และสำหรับ Hyperparameter อื่น ๆ ที่มีผลต่อการเรียนรู้และประสิทธิภาพของโมเดล จะใช้ค่า Default ตามที่กำหนดในตัวอย่างคือ optimizer Adam ที่มี learning rate เท่ากับ 0.01 และ loss function ใช้ categorical_crossentropy
ในการทดสอบ จะนำชุดข้อมูล train มาสร้างโมเดลและใช้ชุดข้อมูล test เพื่อวัดประสิทธิภาพของโมเดล โดยใช้คำสั่ง model.fit ในการสร้างโมเดลด้วยชุด train และใช้ validation_data เพื่อวัดประสิทธิภาพของโมเดลด้วยชุด test สำหรับการวัดผล จะใช้คำสั่ง model.evaluateในการประเมินผลความแม่นยำ (accuracy) ของโมเดล โดยใช้ชุดข้อมูลที่ไม่ได้ใช้ในการเทรนโมเดล (validation set) ในการคำนวณ
โดยการเรียกใช้ model.evaluate จะส่งคืนค่า loss และ accuracy ของโมเดลที่ได้รับการประเมินด้วยชุดข้อมูล validation set ที่ระบุไว้

