
Reinforcement Learning (RL) คือ เทคนิคในการเรียนรู้โดยเป็นการสอนระบบให้เรียนรู้วิธีการตอบสนองต่อสิ่งแวดล้อมแบบใหม่ โดยให้ระบบเรียนรู้จากประสบการณ์ที่ได้รับจากการทดสอบและตอบสนองต่อสิ่งแวดล้อม ซึ่งจะต้องใช้กระบวนการทางคณิตศาสตร์และพื้นฐานทางด้านเทคนิคเข้ามาช่วยเพื่อสร้างการตัดสินใจในการตอบสนองต่อสิ่งแวดล้อมได้ถูกต้อง สามารถนำมาประยุกต์ในการเรียนรู้แบบเสมือนจำลองของการเล่นเกมหรือการทำงานที่มีการตัดสินใจในสถานการณ์ต่าง ๆ โดยมีการระบุ reward หรือค่าตอบแทนเมื่อเราทำได้ถูกต้องหรือผิดพลาดในการตัดสินใจ ใน RL เรามักจะใช้ Markov Decision Process (MDP) ซึ่งเป็นโมเดลทางคณิตศาสตร์ที่ใช้ในการอธิบายปัญหาการตัดสินใจแบบเสี่ยงต่อเวลา (sequential decision making problem) โดย MDP ประกอบด้วย state space, action space, transition probabilities และ reward function
Reinforcement Learning เป็นอัลกอริทึมการเรียนรู้ที่เน้นการตัดสินใจแบบ trial and error โดยมีเป้าหมายเพื่อเรียนรู้แบบอัตโนมัติในสถานการณ์ที่ไม่แน่นอน โดยการใช้ระบบ reward system เพื่อเป็นการกำหนดค่า reward ให้กับ agent หลังจาก agent ทำการกระทำใน environment แล้วให้ agent จัดการปรับแต่งกิจกรรมของตนเองเพื่อเพิ่มโอกาสในการได้รับ reward ที่มากขึ้น โดยแบ่ง Reinforcement Learning ออกเป็นสามส่วนหลักๆ คือ agent, environment และ reward signal
การเน้นการเรียนรู้แบบ trial-and-error โดยใช้ระบบตัวบอกสถานะ (state) และการกระทำ (action) เพื่อปรับแต่งพฤติกรรมของตัว AI agent ให้เหมาะสมกับการแก้ไขปัญหาที่กำหนดไว้ โดย RL จะเน้นการเรียนรู้แบบ incremental โดยใช้ค่า reward ในการวัดความสำเร็จของการกระทำที่ต่างกัน โดยตัว AI agent จะต้องเรียนรู้การวิเคราะห์สถานะ (state) และต้องพยายามปรับแต่งการกระทำ (action) เพื่อให้ได้ค่า reward มากที่สุด
Deep Learning โดย RL ได้รับความนิยมในการใช้ในงาน Robotics, Game AI และงานที่เกี่ยวข้องกับการเดินเรียนรู้แบบต่อเนื่อง (continuous learning) เช่น การเรียนรู้การควบคุมระบบเครือข่ายไฟฟ้า, การเรียนรู้การเล่นเกม (Game Playing), การเรียนรู้การเดินทางของหุ่นยนต์ (Robot Navigation), การเรียนรู้การควบคุมการผลิต (Manufacturing Control) ฯลฯ
ในการใช้ Reinforcement Learning ใน Deep Learning จะมีการเทรนโมเดลโดยการให้ agent ทำงานใน environment โดยจะมีการให้ reward ให้กับ agent ตามผลลัพธ์ที่ได้รับ โดยเทคนิคที่ใช้ในการเรียนรู้ของ agent จะมีหลายแบบ เช่น Q-Learning, Policy Gradient, Actor-Critic เป็นต้น และจะมีการเรียนรู้ไปเรื่อยๆ จนกว่า agent จะสามารถตัดสินใจได้ดีขึ้นตามผลลัพธ์ที่ได้รับเป็นเวลานานพอสมควร
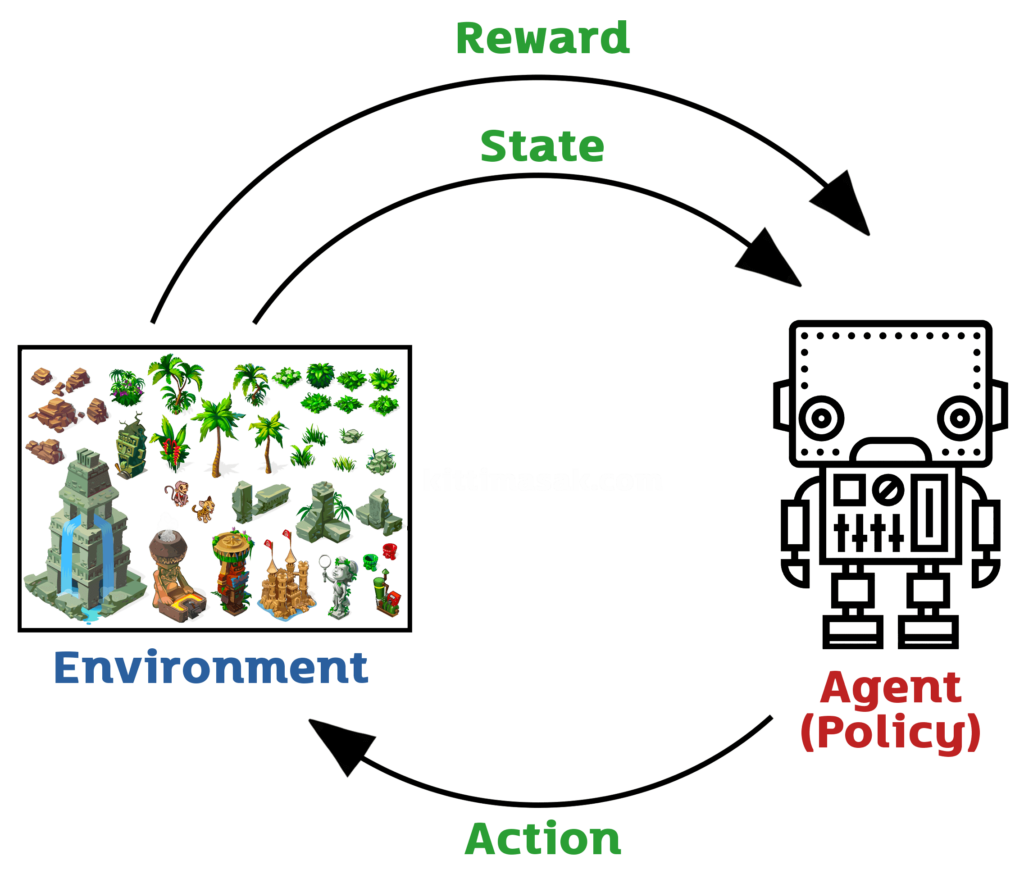
เป็นเทคนิคการเรียนรู้เชิงเส้นทาง (path-based learning) ที่ใช้แนวคิดของการตัดสินใจแบบทดลองและการตอบแทน (trial and reward) เพื่อเรียนรู้และปรับปรุงการกระทำในสถานการณ์ต่างๆ โดย RL นั้นใช้โมเดลเชิงลึก (Deep Learning) เพื่อประมวลผลข้อมูลและสร้างโมเดลที่สามารถเรียนรู้และวิเคราะห์ข้อมูลได้อย่างเป็นมิตรกับคอมพิวเตอร์มากยิ่งขึ้น
ในการใช้ RL ใน Deep Learning จะใช้โครงข่ายประสาทเทียม (Artificial Neural Network) ในการประมวลผลและเรียนรู้โดยโครงข่ายประสาทเทียมจะถูกสร้างขึ้นโดยใช้หลักการ Deep Learning ซึ่งมีการใช้งานหลายๆ แบบ เช่น Convolutional Neural Networks (CNNs) หรือ Recurrent Neural Networks (RNNs) เพื่อทำนายและวิเคราะห์ข้อมูล
Reinforcement Learning (RL) เป็นแนวทางการเรียนรู้ที่ใช้ตัวอย่างสิ่งแวดล้อมจำลองเพื่อเรียนรู้วิธีการจัดการกับสถานการณ์และการกระทำในสิ่งแวดล้อมนั้นๆ
ส่วนประกอบหลักของ Reinforcement Learning ประกอบด้วย
-
Agent
ตัวประมวลผล (computational entity) ที่รับรู้สภาพของสิ่งแวดล้อมและทำการกระทำ ซึ่ง Agent เป็นโมเดลเชิงลึก (Deep Learning Model) ที่เรียนรู้การกระทำจากประสิทธิภาพการกระทำ (action performance) และผลตอบแทน (reward) จากสิ่งแวดล้อม โดยที่โมเดลเชิงลึกนี้จะถูกออกแบบให้สามารถรับรู้สถานะของสิ่งแวดล้อม ทำการตัดสินใจว่าจะทำการกระทำอย่างไร และประมวลผลผลตอบแทน (reward) ที่ได้รับจากการกระทำนั้นๆโมเดลเชิงลึกสามารถใช้กับหลายประเภทของสิ่งแวดล้อม เช่น การเดินของหุ่นยนต์หรือการเล่นเกม โดยโมเดลจะได้รับการเรียนรู้ด้วยวิธีการ backpropagation ที่นำค่าความคลาดเคลื่อน (loss) และผลตอบแทน (reward) มาใช้ในการปรับค่าพารามิเตอร์ของโมเดล ซึ่งจะช่วยปรับปรุงประสิทธิภาพของการตัดสินใจและการกระทำของ Agent ให้ดียิ่งขึ้น
นอกจากนี้ ยังมีการออกแบบโมเดลเชิงลึกแบบอื่นๆ ที่ใช้ใน RL อย่างเช่น Policy Gradient Networks (PGN) ที่ใช้สำหรับการเรียนรู้จากประสิทธิภาพการกระทำแบบไม่ต่อเนื่อง (discrete actions) และ Actor-Critic Networks ที่ใช้สำหรับการเรียนรู้จากประสิทธิภาพการกระทำแบบต่อเนื่อง (continuous actions) โดยจะมีการออกแบบเครือข่ายที่แยกต่างหากสำหรับการตัดสินใจ (policy) และการประเมินค่าผลตอบ
-
Environment
สิ่งแวดล้อมที่ตัวประมวลผลต้องปฏิบัติตาม และได้รับผลตอบแทน (reward) จากการกระทำของตัวประมวลผล ซึ่ง Environment เป็นสิ่งแวดล้อมที่ Agent ต้องทำงานร่วมกันเพื่อเรียนรู้และพัฒนาการกระทำของตนเอง สิ่งแวดล้อมนี้จะให้ข้อมูลต่างๆ ให้กับ Agent เช่น สถานะปัจจุบันของเกม หรือสภาพแวดล้อมรอบตัว ซึ่งจะช่วยให้ Agent ตัดสินใจเลือกการกระทำที่เหมาะสมที่สุดEnvironment สามารถมีความซับซ้อนได้ตามลักษณะของการเรียนรู้ที่ต้องการ โดยสิ่งแวดล้อมอาจเป็นเกมที่มีการเคลื่อนไหวและมีตัวละครหลายตัว หรืออาจเป็นโลกเสมือนที่มีความซับซ้อนและแตกต่างกันไปตามเป้าหมายของการเรียนรู้ ซึ่งจะต้องมีการเตรียมข้อมูลและการออกแบบโมเดลเชิงลึกที่เหมาะสมเพื่อให้ Agent สามารถเรียนรู้และพัฒนาการกระทำของตนเองได้อย่างมีประสิทธิภาพ
Environment จะต้องสามารถให้ข้อมูลเกี่ยวกับสถานะปัจจุบันของตัวเกม หรือสภาพแวดล้อมรอบตัว รวมถึงข้อมูลเกี่ยวกับการกระทำที่ถูกต้องและผลตอบแทนที่ได้รับจากการกระทำนั้นๆ ซึ่งจะช่วยให้ Agent สามารถปรับปรุงการตัดสินใจและการกระทำของตนเองได้อย่างเหมาะสมในแต่ละครั้งที่มีการเรียนรู้ใน RL ใน Deep Learning
-
State
สถานะของสิ่งแวดล้อมที่ตัวประมวลผลมองเห็น ซึ่งเป็นข้อมูลที่ใช้ในการตัดสินใจว่าจะทำการกระทำอย่างไรต่อไป ซึ่ง State เป็นสถานะปัจจุบันของสิ่งแวดล้อม หรือข้อมูลที่ Agent ได้รับมาเพื่อเข้าใจสถานการณ์และตัดสินใจเลือกการกระทำที่เหมาะสม โดย State จะประกอบไปด้วยข้อมูลที่สำคัญสำหรับการตัดสินใจของ Agent เช่น ตำแหน่งของตัวละครในเกม ค่าความเร็วของตัวยาน หรือสภาพแวดล้อมรอบตัว เป็นต้นสถานะปัจจุบันนี้อาจเป็นข้อมูลที่บอกถึงสถานที่ตัว Agent อยู่ในปัจจุบัน หรืออาจเป็นข้อมูลที่บอกถึงสถานะของ Environment ทั้งหมด เช่น สถานะของตัวละครหลายตัวในเกมหรือสถานะของจุดสังเกตุบนแผนที่ สถานะปัจจุบันของ Environment ที่ Agent ต้องการรู้เพื่อตัดสินใจเลือกการกระทำที่เหมาะสมที่สุด เพื่อที่จะได้รับผลตอบแทนที่มากที่สุดจากการกระทำนั้นๆ
สถานะปัจจุบันนี้จะถูกส่งมาให้กับ Agent ในรูปแบบของ state ซึ่งมีลักษณะเป็น vector ของข้อมูลที่บอกถึงสถานะปัจจุบัน ซึ่งจะถูกนำไปใช้ในการคำนวณของโมเดลเชิงลึกเพื่อตัดสินใจเลือกการกระทำที่เหมาะสมที่สุดสำหรับ Agent ในแต่ละสถานะ สิ่งที่สำคัญคือการออกแบบ state ที่เหมาะสมเป็นสิ่งสำคัญใน RL ใน Deep Learning เพราะจะต่อยอดไปสู่ความสามารถในการเรียนรู้และพัฒนาการกระทำของ Agent ให้มีประสิทธิภาพมากขึ้น
-
Action
การกระทำที่ตัวประมวลผลจะทำในสิ่งแวดล้อม เพื่อเปลี่ยนแปลงสถานะของสิ่งแวดล้อม ซึ่งการกระทำที่ Agent เลือกทำในสถานะปัจจุบันของ Environment เพื่อเปลี่ยนแปลงสถานะของ Environment และได้รับผลตอบแทนจาก Environment ตามนโยบาย (policy) ที่ Agent กำหนดไว้Action จะถูกกำหนดในรูปแบบของ vector ที่แทนการกระทำที่เป็นไปได้ทั้งหมดในสถานะปัจจุบัน และ Agent จะต้องเลือก vector ที่ตอบสนองกับนโยบายที่ Agent ต้องการให้เกิดขึ้น
ตัวอย่างเช่นในการเล่นเกม สถานะปัจจุบันจะเป็นสถานะของเกมที่ Agent อยู่ และ Action จะเป็นการกดปุ่มหรือกระทำที่ทำให้ตัวละครเคลื่อนที่หรือกระทำอื่นๆ ซึ่งจะส่งผลต่อสถานะของเกม และ Agent จะได้รับผลตอบแทนตามนโยบายที่ตั้งไว้ สิ่งที่สำคัญคือการออกแบบ action ที่เหมาะสมเป็นสิ่งสำคัญใน RL ใน Deep Learning เพราะจะมีผลต่อประสิทธิภาพของ Agent ในการเลือก action ที่มีผลตอบแทนสูงสุดในสถานะปัจจุบัน
-
Reward
ผลตอบแทนที่ตัวประมวลผลได้รับหลังจากทำการกระทำ ซึ่งมักจะเป็นค่าคะแนนหรือค่าตัวเลขที่บอกถึงคุณภาพของการกระทำนั้นๆ ซึ่งผลตอบแทนที่ Agent ได้รับจาก Environment เมื่อ Agent กระทำ Action ในสถานะปัจจุบัน โดย Reward จะบอกให้ Agent ทราบว่า Action ที่เลือกในสถานะปัจจุบันนั้นเป็นการกระทำที่ดีหรือไม่ดีต่อการทำงานของ Agent โดยจะถูกกำหนดเป็นค่าจำนวนจริง (real number)ตัวอย่างเช่นในการเล่นเกม การเลื่อนหรือการตีกลับบอลในเกมฟุตบอลอาจจะได้รับ Reward ตามจำนวนประตูที่ได้ทำหรือเสียในช่วงเวลาหนึ่งๆ ซึ่งถ้าเป็นการทำให้ได้ประตู Agent จะได้รับ Reward บวกในขณะที่การเสียประตู Agent จะได้รับ Reward ลบ
การออกแบบ Reward ที่เหมาะสมเป็นสิ่งสำคัญใน RL ใน Deep Learning เพราะจะมีผลต่อประสิทธิภาพของ Agent ในการเรียนรู้นโยบายที่ดีที่สุด และเป็นการกำหนดตัวชี้วัดว่า Agent ได้ปฏิบัติตามความต้องการของผู้ออกแบบโมเดลหรือไม่
-
Policy
กฎการตัดสินใจ (decision-making rules) ที่ใช้ในการเลือกการกระทำของตัวประมวลผลโดยอิงจากสถานะและข้อมูลอื่นๆ ซึ่งกฎเชิงการกระทำ (rule of action) ซึ่งกำหนดวิธีการเลือก Action ที่ Agent จะกระทำในสถานะปัจจุบันของ Environment โดยอาจเป็นการเลือก Action ด้วยความน่าจะเป็น (probabilistic policy) หรือการเลือก Action ที่เป็นที่แน่นอน (deterministic policy) ที่สำคัญ Policy สามารถถูกแทนด้วย Neural Network ที่รับ Input เป็น State แล้ว Output เป็น Distribution ของ Probability ของ Action ที่ Agent จะกระทำในสถานะปัจจุบันการเลือก Policy ที่เหมาะสมเป็นสิ่งสำคัญใน RL ใน Deep Learning เพราะจะมีผลต่อประสิทธิภาพของ Agent ในการเรียนรู้นโยบายที่ดีที่สุด และสามารถแก้ไขปัญหาความไม่แน่นอนได้ เช่น ในการเดินทางของหุ้น การทำนายว่าค่าหุ้นจะเพิ่มขึ้นหรือลดลงในอนาคตนั้นเป็นการทำนายที่ไม่แน่นอน ดังนั้น Agent จะต้องเลือก Policy ที่สามารถปรับการกระทำได้โดยพิจารณา Reward ที่ได้รับในอดีตและความเป็นไปได้ของสถานะปัจจุบันของ Environment
-
Value function
ฟังก์ชันที่ใช้วัดคุณค่าของสถานะและการกระทำ ซึ่งมักจะถูกใช้ในการประมาณค่าผลตอบแทนที่จะได้รับจากการกระทำ ซึ่งฟังก์ชันที่ใช้สำหรับประเมินค่าความเหมาะสมของสถานะ (State) หรือคู่สถานะและการกระทำ (State-Action pair) โดยแต่ละค่าของ Value function จะแสดงค่าความคุ้มค่า (value) ของการอยู่ในสถานะหรือการกระทำนั้น ๆ โดยค่า Value function สามารถใช้สำหรับช่วยในการตัดสินใจเลือก Action ที่เหมาะสมในแต่ละสถานะValue function สามารถถูกจำลองด้วย Neural Network ซึ่งจะรับ Input เป็น State หรือ State-Action pair และ Output เป็นค่าความคุ้มค่า (Value) ของสถานะหรือการกระทำนั้น ๆ โดยโมเดลจะถูกเทรนด้วยข้อมูล Reward และ State ที่เกี่ยวข้องกับการกระทำที่ผ่านมา
การใช้ Value function ใน RL ใน Deep Learning สามารถช่วยในการเรียนรู้นโยบายที่ดีที่สุดได้ โดยใช้โมเดลที่ได้รับการเทรนไว้อย่างเหมาะสมในการตัดสินใจเลือก Action ที่จะกระทำในสถานะปัจจุบัน ซึ่งสามารถช่วยเพิ่มประสิทธิภาพของ Agent ในการเรียนรู้นโยบายที่ดีที่สุดได้
Value function สามารถแบ่งออก 2 ประเภท คือ State-value function และ Action-value function (หรือ Q-function) โดยทั่วไปแล้ว Action-value function จะถูกใช้ในการเรียนรู้นโยบายแบบ off-policy ในขณะที่ State-value function จะถูกใช้ในการเรียนรู้นโยบายแบบ on-policy โดยมีรายละเอียดดังนี้
– State-value function
เป็นฟังก์ชันที่ใช้ประเมินค่าความคุ้มค่าของแต่ละสถานะ (state) ใน reinforcement learning โดยที่ไม่ระบุ Action ที่จะดำเนินการ โดยประกาศได้ดังนี้V(s) = E[G_t | S_t = s]
โดยที่
- V(s) คือ ค่าความคุ้มค่าของสถานะ s
- E[G_t | S_t = s] คือ ค่าคาดหมายของ Return (รางวัลรวม) ที่จะได้รับตั้งแต่เวลาปัจจุบัน t ถ้าเริ่มต้นจากสถานะ s
สำหรับการประเมินค่า V(s) นั้น จะใช้หลักการของ Bellman equation ที่เป็นการจับคู่ระหว่างค่าความคุ้มค่าปัจจุบันกับค่าความคุ้มค่าในขั้นตอนต่อไปเพื่อปรับปรุงค่า V(s) ได้ดังนี้
V(s) = E[G_t | S_t = s]
= E[R_t+1 + γV(S_t+1) | S_t = s] (โดยที่ γ เป็น discount factor)
= Σ_a π(a|s) Σ_s’ P(s’|s,a)[R(s,a,s’) + γV(s’)]
โดยที่
- Σ_a คือ การบวกทุก Action ที่เป็นไปได้ในสถานะ s
- π(a|s) คือ นโยบาย (policy) ที่กำหนดว่า Agent จะดำเนินการ Action a ในสถานะ s
- Σ_s’ คือ การบวกทุกสถานะที่เป็นไปได้ในขั้นตอนต่อไป
- P(s’|s,a) คือ ฟังก์ชันการเปลี่ยนสถานะที่ระบุว่า Action a ในสถานะ s จะเปลี่ยนสถานะเป็น s’ ด้วยความน่าจะเป็นเท่าไหร่
- R(s,a,s’) คือ รางวัลที่ได้รับเมื่อทำ Action a ในสถานะ s แล้วเปลี่ยนสถานะเป็น s’
– Action-value function
เป็นฟังก์ชันที่ใช้ประเมินค่าความคุ้มค่าของการกระทำ (action) ใน reinforcement learning โดยใช้ state ที่ Agent อยู่ปัจจุบันเป็นพารามิเตอร์ โดยที่ไม่ระบุ state ที่จะเข้าถึง โดยประกาศได้ดังนี้Q(s, a) = E[G_t | S_t = s, A_t = a]
โดยที่
- Q(s, a) คือ ค่าความคุ้มค่าของการกระทำ a ในสถานะ s
- E[G_t | S_t = s, A_t = a] คือ ค่าคาดหมายของ Return (รางวัลรวม) ที่จะได้รับตั้งแต่เวลาปัจจุบัน t ถ้าเริ่มต้นจากสถานะ s และทำ Action a
การประเมินค่า Q(s,a) นั้นสามารถใช้หลักการของ Bellman equation ในการปรับปรุงค่า Q(s,a) ได้ดังนี้
Q(s,a) = E[G_t | S_t = s, A_t = a]
= E[R_t+1 + γQ(S_t+1, A_t+1) | S_t = s, A_t = a]
= Σ_s’ P(s’|s,a) Σ_a’ π(a’|s’)[R(s,a,s’) + γQ(s’,a’)]
โดยที่
- Σ_s’ คือ การบวกทุกสถานะที่เป็นไปได้ในขั้นตอนต่อไป
- P(s’|s,a) คือฟังก์ชันการเปลี่ยนสถานะที่ระบุว่า Action a ในสถานะ s จะเปลี่ยนสถานะเป็น s’ ด้วยความน่าจะเป็นเท่าไหร่
- Σ_a’ คือ การบวกทุก Action ที่เป็นไปได้ในสถานะ s’
- π(a’|s’) คือ นโยบาย (policy) ที่กำหนดว่า Agent จะดำเนินการ Action a’ ในสถานะ s’
- R(s,a,s’) คือ รางวัลที่ได้รับเมื่อทำ Action a ในสถานะ s แล้วเปลี่ยนสถานะเป็น s’
- γ เป็น discount factor ที่ใช้ในการปรับลดค่ารางวัล (reward) ในอนาคต
- γQ(s’,a’) คือ ค่าคาดการณ์รางวัลสูงสุดในขั้นตอนต่อไปที่เป็นไปได้ในสถานะ s’ และดำเนินการ Action a’
การเขียน Python โดยใช้ Reinforcement Learning ใน Deep Learning
จะใช้ไลบรารีหลายตัว ซึ่งจะต้องทำการติดตั้งก่อนใช้งาน โดยตัวอย่างของไลบรารีที่จะใช้เช่น Tensorflow, Keras, PyTorch, OpenAI Gym, NumPy, Matplotlib เป็นต้น โดยมีรายละเอียดดังนี้
- การกำหนด Environment
โดยใช้ OpenAI Gym โดย OpenAI Gym เป็นไลบรารีที่ใช้สำหรับสร้าง Environment สำหรับการฝึกฝนโมเดล Reinforcement Learning โดยให้มี Environment พร้อมใช้งานเรียบร้อยแล้ว เช่น CartPole, MountainCar, Atari games เป็นต้น - การกำหนดโมเดล Deep Learning
โดยใช้ไลบรารีต่าง ๆ เช่น Tensorflow, Keras, PyTorch เพื่อสร้างโมเดล Neural Network สำหรับการประมวลผลข้อมูล - การกำหนด Agent และ Policy
โดย Agent เป็นตัวเลือก Action ในแต่ละสถานะของ Environment ตามนโยบาย (policy) ที่กำหนด ซึ่งมักใช้ Q-learning, SARSA, Deep Q-Network (DQN) เป็นต้น -
การกำหนดการคำนวณ Reward
โดยการกำหนด Reward จะใช้ฟังก์ชันที่เรียกว่า Reward function เพื่อให้ Agent ได้รับคะแนนรางวัลตามผลลัพธ์ที่ได้จาก Action ที่ Agent ได้ทำในแต่ละสถานะ -
การสร้าง Loop สำหรับการเทรนโมเดล
โดยการเทรนโมเดลจะเริ่มต้นด้วยการกำหนดสถานะเริ่มต้น (initial state) ของ Environment และให้ Agent เลือก Action ตามนโยบาย (policy) ที่กำหนด จากนั้นจะคำนวณ Reward ที่ได้รับจากการทำ Action -
การเลือกและสร้างโมเดล
โมเดลที่ใช้ใน Reinforcement Learning จะต้องเหมาะสมกับประเภทงานและสภาพแวดล้อมที่ใช้ รวมถึงสามารถจำลองการกระทำของ Agent ได้ตรงตามแผนที่เราต้องการ โดยโมเดลที่ใช้บ่อยที่สุดคือ Deep Q-Networks (DQN) และ Policy Gradient (PG) โดย DQN ใช้เครือข่ายประสาทเทียม (neural network) ในการคำนวณ Q-value ของ State-action pair และ PG ใช้เครือข่ายประสาทเทียมในการประมาณการค่าของนโยบาย (policy) ในแต่ละสถานะ -
การกำหนด Hyperparameters
ในการเทรนโมเดล Reinforcement Learning จะต้องกำหนด Hyperparameters หรือพารามิเตอร์ที่ไม่ได้ถูกเรียนรู้จากโมเดล เช่น อัตราการเรียนรู้ (learning rate) และค่า Gamma ซึ่งเป็น discount factor ที่ใช้ในการคำนวณค่ารางวัลที่ได้รับในอนาคต การกำหนด Hyperparameters ที่เหมาะสมจะช่วยให้โมเดลมีประสิทธิภาพและเรียนรู้ได้เร็วขึ้น -
การเลือกและปรับแต่ง Algorithm
มีหลาย Algorithm ที่ใช้ใน Reinforcement Learning เช่น Q-Learning, SARSA, DDPG, A3C เป็นต้น โดยการเลือก Algorithm ที่เหมาะสมกับงานและข้อมูลที่ใช้จะช่วยให้โมเดลมีประสิทธิภาพและเรียนรู้ได้ดีขึ้น
ตัวอย่าง การที่ใช้ Reinforcement Learning โดยใช้ Keras เป็นตัวช่วยในการสร้างโมเดล Neural Network และ OpenAI Gym เป็นระบบ simulation environment สำหรับการฝึกโมเดล โดนจะใช้ Deep Q-Network (DQN) algorithm ซึ่งเป็นการเรียนรู้แบบไม่มีผู้สอน (unsupervised learning) โดยโมเดลจะเรียนรู้จากการทำงานใน environment โดยไม่มีคำตอบ (ไม่มี label) แต่จะใช้รางวัล (reward) เป็นตัวกำกับในการเรียนรู้ ในการเรียนรู้การเล่นเกม CartPole ของ OpenAI Gym
import gym
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
class DQNAgent:
def init(self, state_size, action_size):
self.state_size = state_size # ขนาดของสถานะ
self.action_size = action_size # ขนาดของการกระทำ
self.memory = [] # เก็บประสบการณ์เพื่อใช้ในการเล่นซ้ำ
self.gamma = 0.95 # ค่าลดลงสำหรับรางวัลในอนาคต
self.epsilon = 1.0 # อัตราการสำรวจ
self.epsilon_min = 0.01 # อัตราการสำรวจขั้นต่ำ
self.epsilon_decay = 0.995 # อัตราการลดลงสำหรับความน่าจะเป็นในการสำรวจ
self.learning_rate = 0.001 # อัตราการเรียนรู้
self.model = self._build_model()
def _build_model(self):
# สร้างโมเดลเน็ตเวิร์คที่ประมาณค่า Q-value function
model = Sequential()
# ชั้นแรกของโมเดลเน็ตเวิร์คที่มีโหนดขนาด state_size และฟังก์ชันเรลู (ReLU)
model.add(Dense(24, input_dim=self.state_size, activation='relu'))
# ชั้นซ่อนที่มีโหนด 24 และฟังก์ชันเรลู (ReLU)
model.add(Dense(24, activation='relu'))
# ชั้นเอาท์พุทที่มีโหนดขนาด action_size และฟังก์ชันเชิงเส้น (linear)
model.add(Dense(self.action_size, activation='linear'))
# คอมไพล์โมเดลด้วยค่าสูญเสียเฉลี่ยที่สุด (mean squared error loss) และออพติไมเซอร์แบบ Adam ด้วยอัตราการเรียนรู้
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
return model
def remember(self, state, action, reward, next_state, done):
# บันทึกประสบการณ์เพื่อนำมาใช้ในการเล่นซ้ำ
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
# เลือกการกระทำโดยใช้อัตราการสำรวจแบบอ
if np.random.rand() <= self.epsilon:
# Exploration: Randomly choose any action
return np.random.choice(self.action_size)
else:
# Exploitation: Choose the action that gives the highest predicted Q-value
return np.argmax(self.model.predict(state)[0])
def replay(self, batch_size):
# Sample a batch of experiences from memory to be used for replay
minibatch = np.random.choice(len(self.memory), batch_size, replace=False)
for i in minibatch:
state, action, reward, next_state, done = self.memory[i]
# Calculate the target Q-value
target = reward
if not done:
target = reward + self.gamma * np.amax(self.model.predict(next_state)[0])
# Update the Q-value estimate for the action taken in the current state
target_f = self.model.predict(state)
target_f[0][action] = target
# Train the neural network with one epoch on the updated Q-value estimate
self.model.fit(state, target_f, epochs=1, verbose=0)
# Decay the exploration rate
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
จากตัวอย่างนี้เราจะใช้ OpenAI Gym เป็น environment ในการฝึกโมเดล โดยเราจะใช้ environment ชื่อ ‘CartPole-v1’ ซึ่งเป็นการทำงานของการทดสอบ control system การสร้าง DQNAgent (Deep Q-Network Agent) ในการแก้ปัญหาของ OpenAI Gym เกมแบบ CartPole-v1 โดยใช้ Deep Learning และ Reinforcement Learning โดย gym คือ library ที่ใช้สร้าง environment สำหรับการฝึกสอน AI ซึ่งในตัวอย่างนี้เราใช้ CartPole environment
โดยสร้างคลาส DQNAgent ซึ่งมีฟังก์ชันต่างๆดังนี้
- init: กำหนดค่าต่างๆเช่น ขนาดของ state และ action, memory, gamma (discount factor), epsilon (exploration rate), learning rate และสร้างโมเดล
- _build_model: สร้างโมเดล Neural Network โดยใช้ Keras
- remember: เก็บข้อมูลจากการทำงาน (state, action, reward, next_state, done) ไว้ใน memory
- act: สร้างการกระทำโดยการเลือก action ตามการสุ่มหรือการทำนายของโมเดล
- replay: ใช้ในการเรียนรู้โมเดล โดย replay จะสุ่มตัวอย่างจากประวัติ (memory) ของตัวเอง แล้วนำมาเรียนรู้เพื่อปรับปรุงโมเดล
การสร้าง DQNAgent ที่ใช้ Deep Q-Network (DQN) ในการเรียนรู้การเล่นเกมใน OpenAI Gym environment หรือเกมอื่น ๆ โดยการใช้โมเดล Neural Network สำหรับการประมาณค่า Q-value ของแต่ละ state-action pair โดยโมเดลจะเรียนรู้จาก memory ของ agent ซึ่งจะเก็บประวัติการทำงานที่ผ่านมา และจะใช้โมเดลที่เรียนรู้ได้ในการตัดสินใจในการดำเนินการในแต่ละ state โดยใช้การเลือก Action จากการสุ่มเลือก Action โดยมีความน่าจะเป็น ε (epsilon) สำหรับการสุ่มและ (1-ε) สำหรับการเลือก Action ที่มีค่า Q-value สูงที่สุด ในแต่ละสถานะ state โดย epsilon จะลดลงตามเวลาเพื่อเพิ่มประสิทธิภาพของการเรียนรู้ของ Agent ด้วยการเรียนรู้จากประวัติการทำงานที่ผ่านมา (experience replay) และการใช้งาน DQN ทำให้ Agent สามารถเรียนรู้ได้อย่างมีประสิทธิภาพในการเล่นเกมหรือการประยุกต์ใช้ในงานอื่น ๆ ที่เกี่ยวกับ Reinforcement Learning และ Deep Learning
ตัวอย่าง การใช้ Reinforcement Learning โดยใช้ขั้นตอนการเรียนรู้ Q-Learning แบบแบ่งปันประสบการณ์ (Experience Replay) ซึ่งใช้ Keras สำหรับสร้างโมเดล Deep Q-Network (DQN) ในการเรียนรู้การเล่นเกม CartPole ของ OpenAI Gym
import gym # import gym เพื่อใช้งาน environment ในการทดสอบ agent
import numpy as np # import numpy เพื่อใช้งาน array และ math operations
from keras.models import Sequential # import Sequential เพื่อสร้าง neural network model
from keras.layers import Dense # import Dense เพื่อสร้าง layers ของ neural network
from keras.optimizers import Adam # import Adam เพื่อใช้เป็น optimizer ในการเทรน neural network
class DQNAgent:
def init(self, state_size, action_size):
self.state_size = state_size # จำนวน state variables
self.action_size = action_size # จำนวน actions ที่ agent สามารถเลือกได้
self.memory = [] # ระบบเก็บข้อมูลเพื่อนำมาเทรน agent
self.gamma = 0.95 # ค่า discount factor ในการคำนวณค่า Q value
self.epsilon = 1.0 # ค่าเริ่มต้นของ epsilon (สำหรับ exploration-exploitation tradeoff)
self.epsilon_min = 0.01 # ค่า epsilon ที่น้อยที่สุดที่ agent จะใช้
self.epsilon_decay = 0.995 # ค่าที่ใช้ในการลด epsilon ทุก episode
self.learning_rate = 0.001 # อัตราการเรียนรู้ของ agent
self.model = self._build_model() # สร้าง neural network model สำหรับการเรียนรู้ Q-value
def _build_model(self):
model = Sequential() # สร้าง Sequential model
model.add(Dense(24, input_dim=self.state_size, activation='relu')) # เพิ่ม input layer ด้วย 24 nodes
model.add(Dense(24, activation='relu')) # เพิ่ม hidden layer ด้วย 24 nodes
model.add(Dense(self.action_size, activation='linear')) # เพิ่ม output layer ด้วย nodes ตามจำนวน actions
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate)) # compile model ใช้ mse loss และ Adam optimizer
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done)) # เพิ่มข้อมูลการทำงานลงใน memory
def act(self, state):
if np.random.rand() <= self.epsilon:
return np.random.choice(self.action_size) # สุ่ม action ที่จะทำ (สำหรับการสำรวจ)
else:
return np.argmax(self.model.predict(state)[0]) # ใช้ model ที่เรียนรู้ Q-value เพื่อเลือก action (สำหรับ exploitation)
def replay(self, batch_size):
minibatch = np.random.choice(len(self.memory), batch_size, replace=False)
for i in minibatch:
state, action, reward, next_state, done = self.memory[i]
target = reward
if not done:
target = reward + self.gamma * np.amax(self.model.predict(next_state)[0])
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
if __name__ == "__main__":
env = gym.make('CartPole-v0')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DQNAgent(state_size, action_size)
episodes = 1000
for e in range(episodes):
state = env.reset()
state = np.reshape(state, [1, state_size])
done = False
time = 0
while not done:
env.render()
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
reward = reward if not done else -10
next_state = np.reshape(next_state, [1, state_size])
agent.remember(state, action, reward, next_state, done)
state = next_state
time += 1
if done:
print("episode: {}/{}, score: {}, e: {:.2}"
.format(e, episodes, time, agent.epsilon))
break
if len(agent.memory) > batch_size:
agent.replay(batch_size)จากตัวอย่าง เป็นการสร้าง DQN Agent สำหรับเล่นเกม CartPole-v0 โดยใช้ deep learning ในการสร้างโมเดล neural network โดยใช้ Keras และ TensorFlow เป็น backend
DQNAgent มีเมทอด _build_model ที่ใช้สร้างโมเดล neural network โดยมี 3 layers ซึ่งมี input ขนาด state_size และ output ขนาด action_size โดยใช้ activation function เป็น relu ใน layer 1 และ 2 และใช้ linear activation function ใน output layer
DQNAgent มีเมทอด remember ที่ใช้เก็บประวัติการเล่นเกมลงใน memory
DQNAgent มีเมทอด act ที่ใช้สุ่มเลือก action จาก model หรือ random choice ตามค่า epsilon
DQNAgent มีเมทอด replay ที่ใช้สร้าง minibatch จาก memory แล้ว train model โดยใช้ประวัติของเกมใน minibatch นี้
ในส่วนของ main จะสร้าง environment ของเกม CartPole-v0 และสร้าง DQNAgent ด้วย state size และ action size จาก environment และเริ่มต้นการเล่นเกม ซึ่งจะเรียกใช้ method act ของ agent เพื่อให้ agent เลือก action ต่อไป และเรียกใช้ method remember เพื่อเก็บประวัติเกมลงใน memory จากนั้น agent จะเล่นเกมต่อจนกว่าเกมจะจบลงหรือถึงจำนวน episode ที่กำหนด แล้วจึงจะเรียกใช้ method replay ของ agent เพื่อเทรน model ใน minibatch ที่สุ่มมาจาก memory ที่เก็บรวบรวมไว้ก่อนหน้านี้
การใช้ DQN (Deep Q-Network) ในการสร้างตัวแทน (agent) สำหรับการเรียนรู้ในเกม CartPole ซึ่งเป็นเกมแนวคิดของ OpenAI Gym ที่ให้แต้มคะแนนตามเวลาที่สามารถควบคุมตัวรถเข็นให้ไม่ล้มลงได้ยาวขึ้น การทำงานของ DQNAgent แบ่งออกเป็นหลายส่วน ดังนี้
- ส่วนที่ 1: กำหนดค่าต่างๆ ในการสร้าง DQNAgent ได้แก่ ขนาดของ state และ action จำนวนที่จะเก็บใน memory ตัวแปรสำหรับส่วนสำคัญในการเรียนรู้ เช่น gamma, epsilon, learning_rate และฟังก์ชัน model ที่เก็บเป็นคลาส DQNAgent และมีฟังก์ชันเอาไว้สำหรับสร้าง model ด้วย Keras โดยใช้ Dense layer 3 ชั้น โดยใช้ activation function ที่เหมาะสมกับแต่ละชั้น รวมทั้งใช้ Adam optimizer ในการค้นหาค่าน้ำหนักและ bias ที่เหมาะสมสำหรับการทำนาย output
- ส่วนที่ 2: มีฟังก์ชันสำหรับเก็บข้อมูล (remember) เพื่อจะใช้สำหรับการเรียนรู้ในภายหลัง ซึ่งมี parameter ประกอบด้วย state, action, reward, next_state และ done ซึ่งเป็นตัวแปรสำหรับบอกว่าเกมส์จบหรือยัง โดยทั่วไปแล้วจะใช้ done เป็น True เมื่อตัวรถเข็นล้มหรือไม่สามารถควบคุมตัวรถเข็นให้มีความสมดุลได้
- ส่วนที่ 3: มีฟังก์ชัน
replayซึ่งใช้สำหรับการฝึกสอนโมเดล โดยสุ่มสร้างเป็นชุดข้อมูลขนาดbatch_sizeจากmemoryของ agent ที่เก็บข้อมูลของการเล่นที่ผ่านมา จากนั้นทำการคำนวณค่า target จาก reward และค่า Q-value ของ next state ด้วย gamma และหาค่า Q-value ของ state ปัจจุบัน (target_f) จากนั้นอัพเดทค่า Q-value ของ action ที่ตัดสินใจเลือกไปด้วยค่า target และนำข้อมูลมาเรียนรู้ด้วยฟังก์ชัน fit ของโมเดล ในกรณีที่ epsilon มากกว่า epsilon_min ก็จะลดค่า epsilon ลงตามค่า epsilon_decay ที่กำหนดไว้ก่อนหน้านี้

