
Multiple Regression คือ การใช้โมเดลสถิติหรือ Machine Learning ในการสร้างสมการที่สามารถใช้ทำนายผลลัพธ์หรือตัวแปรเป้าหมายได้โดยพิจารณาผลกระทบของตัวแปรต้นหลายตัว โดยสมการที่ได้จะเป็นเชิงเส้นหรือเชิงโครงสร้าง (linear or structured) ก็แบ่งออกเป็นหลายแบบ แต่ที่เป็นที่สุดคือ Multiple Linear Regression หรือ การใช้หลายตัวแปรต้นในการประมาณค่าผลลัพธ์หรือตัวแปรเป้าหมาย โดยสมการที่ได้จะเป็นเชิงเส้นหรือสมการเชิงโครงสร้าง ซึ่งใน Machine Learning จะนิยมใช้วิธี Gradient Descent หรือวิธีการทางคณิตศาสตร์อื่นๆ เพื่อหาค่าพารามิเตอร์ที่เหมาะสมที่สุด
เมื่อเทียบกับ Linear Regression ซึ่งใช้ตัวแปรต้นเพียงตัวเดียว การใช้ Multiple Regression จะช่วยให้เราสามารถสร้างโมเดลที่แม่นยำขึ้นด้วยการพิจารณาผลกระทบของตัวแปรต้นหลายตัว ซึ่งเหมาะสำหรับการทำนายผลลัพธ์ที่ซับซ้อนและมีผลการกระทบจากหลายตัวแปร
Multiple Regression เป็นการสร้างโมเดลที่ใช้หลายตัวแปรเพื่อพยากรณ์ผลลัพธ์หนึ่ง โดยตัวแปรที่ใช้จะต้องมีความสัมพันธ์กัน เช่น ความสูง, น้ำหนัก, และอายุของผู้ประกอบการอาหารอาหารกับรายได้ของร้านอาหาร
ใน Multiple Regression จะมีตัวแปรอิสระหลายตัว (x1, x2, x3,…,xn) และตัวแปรตามหนึ่งตัว (y) ที่ต้องการพยากรณ์ โดยการสร้างโมเดล Multiple Regression จะใช้ข้อมูลประวัติศาสตร์เพื่อเรียนรู้และหาความสัมพันธ์ระหว่างตัวแปรอิสระและตัวแปรตาม เพื่อทำนายผลลัพธ์ตัวแปรตามที่ต้องการ ตัวอย่างเช่น การพยากรณ์ราคาของบ้านด้วยตัวแปรอิสระหลายตัว เช่น พื้นที่บ้าน, จำนวนห้องนอน, จำนวนห้องน้ำ, ระยะทางจากตัวเมือง และอื่นๆ
การสร้างโมเดล Multiple Regression ใน Machine Learning สามารถใช้ไลบรารีต่างๆ เช่น Scikit-learn, TensorFlow, Keras, หรือ PyTorch ได้ โดย Scikit-learn เป็นไลบรารีที่มักถูกนำมาใช้ในการสร้างโมเดล Multiple Regression มากที่สุดใน Python โดยทั่วไป
Multiple Regression สามารถนำมาใช้งานได้ในหลายแบบ เช่น การพยากรณ์ราคาบ้าน การประเมินค่าอสังหาริมทรัพย์ หรือการทำนายผลผลิตของพืช โดยใช้ตัวแปรหลายตัว ซึ่งสามารถอธิบายผลตอบแทนได้ดีกว่าการใช้ Linear Regression ที่ใช้ตัวแปรเดียว
Multiple Regression เป็นการใช้โมเดล Linear Regression ในการทำนายค่าตัวแปรเป้าหมาย (dependent variable) จากตัวแปรอิสระ (independent variables) หลายตัว โดยมีสมการในรูปแบบดังนี้:
y = b0 + b1x1 + b2x2 + … + bn*xn
โดยที่ y คือค่าตัวแปรเป้าหมายที่ต้องการทำนาย (dependent variable) และ x1,x2,…,xn เป็นตัวแปรอิสระ (independent variables) หลายตัว แต่ละตัวมีน้ำหนัก (coefficient) คือ b1,b2,…,bn ตามลำดับ และ b0 คือค่าคงที่ (intercept) ที่แทนค่า y เมื่อ x1,x2,…,xn เป็นศูนย์ทั้งหมด
ในการประยุกต์ใช้ Multiple Regression ใน Machine Learning จะต้องมีข้อมูล (dataset) ที่มีค่าตัวแปรอิสระและตัวแปรเป้าหมาย และสามารถใช้งานได้กับชุดข้อมูลที่มีมากกว่าหนึ่งตัวแปรอิสระ โดยใช้หลักการเดียวกับ Linear Regression ในการคำนวณค่าน้ำหนักแต่ละตัวแปรอิสระ (coefficient) และค่าคงที่ (intercept) ที่ใช้ในการทำนายค่าตัวแปรเป้าหมาย (dependent variable) จากตัวแปรอิสระ (independent variables)
การเขียน Python โดยใช้ Multiple Regression นั้น เราต้องมีข้อมูลตัวอย่างที่เหมาะสม โดยที่ข้อมูลตัวอย่างจะต้องประกอบไปด้วยตัวแปรต้นหรือ Features หลายตัวและตัวแปรตามหรือ Target Variable เพียงตัวเดียว และเราจะต้องทำการแบ่งข้อมูลออกเป็นชุด Training Data และ Test Data เพื่อใช้ในการ Train และ Evaluate โมเดลของเรา
การเขียน Python โดยใช้ Multiple Regression มีขั้นตอนดังนี้
-
Import Libraries เริ่มต้นด้วยการ Import Libraries ที่จำเป็นต้องใช้ เช่น pandas, numpy, matplotlib, และ sklearn
-
Collect Data นำข้อมูลตัวอย่างที่มีตัวแปรต้นหลายตัวและตัวแปรตามเพียงตัวเดียว และแบ่งข้อมูลเป็นชุด Training Data และ Test Data
-
Train Model สร้างโมเดล Linear Regression และ Train โมเดลด้วยชุด Training Data
-
Evaluate Model ใช้ Test Data เพื่อทำการประเมินค่า Mean Squared Error (MSE) และ R-squared score เพื่อดูว่าโมเดลของเรามีประสิทธิภาพมากน้อยแค่ไหนในการทำนายค่าตัวแปรตาม
-
Predictions นำโมเดลที่ Train ไว้มาใช้ในการทำนายค่าตัวแปรตามข้อมูลตัวอย่างใหม่
-
Visualize Results สุดท้ายเราสามารถใช้ matplotlib เพื่อสร้างกราฟแสดงผลลัพธ์การทำนายของโมเดล
ตัวอย่าง การทำนายผลผลิตของข้าวในภาคอีสานของประเทศไทย โดยจะใช้ตัวแปรหลายตัว เช่น ปริมาณน้ำฝน อุณหภูมิ ความชื้น ระยะเวลาที่ใช้ในการปลูก โดยการใช้ Multiple Regression เราสามารถหาสมการที่อธิบายผลตอบแทนได้ดีขึ้น และสามารถใช้สมการนั้นในการทำนายผลผลิตของข้าวในเวลาต่อไปได้ แสดงการเขียน Python ได้ดังนี้
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
# ข้อมูลการปลูกข้าว
data = {
'rainfall': [100, 150, 200, 300, 250, 200, 150, 100, 50, 25],
'temperature': [30, 29, 28, 27, 26, 25, 24, 23, 22, 21],
'humidity': [80, 85, 90, 85, 80, 75, 70, 75, 80, 85],
'time': [120, 130, 140, 150, 160, 170, 180, 190, 200, 210],
'yield': [50, 55, 60, 70, 65, 75, 80, 85, 90, 95]
}
# แปลงข้อมูลเป็น DataFrame
df = pd.DataFrame(data)
# แบ่งข้อมูลเป็น features และ target variable
X = df[['rainfall', 'temperature', 'humidity', 'time']]
y = df['yield']
# สร้างโมเดล Linear Regression
model = LinearRegression()
# Train โมเดล
model.fit(X, y)
# ทำนายผลผลิตข้าว
prediction = model.predict(X)
# แสดงผลลัพธ์
print(prediction)
# แสดงกราฟ
sns.regplot(x=prediction, y=y)
plt.xlabel('Predicted Yield')
plt.ylabel('Actual Yield')
plt.title('Actual vs Predicted Yield')
plt.show()ผลลัพธ์ที่ได้ คือ
[49.53633503 55.17275242 60.80916982 65.84596946 70.308758 74.77154654
79.23433507 84.48807839 89.74182171 95.09123355]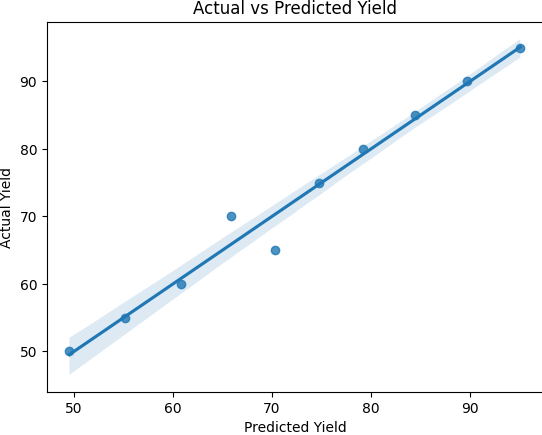
ตัวอย่าง
การสร้าง Multiple Regression model ด้วย Python จะต้องใช้โมดูลหลายๆ โมดูลเหล่านี้ได้แก่ pandas, numpy, matplotlib, sklearn.linear_model, sklearn.metrics, และ sklearn.model_selection โดยสามารถเขียนได้ดังนี้
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
# สร้างข้อมูลเพื่อใช้เป็นตัวอย่าง
np.random.seed(0)
n = 1000
x1 = np.random.randn(n) * 10
x2 = np.random.randn(n) * 5
x3 = np.random.randn(n) * 2
y = 2*x1 + 3*x2 - 4*x3 + 10 + np.random.randn(n)*3
data = pd.DataFrame({'x1': x1, 'x2': x2, 'x3': x3, 'y': y})
# แบ่งข้อมูลเป็น train set และ test set
X_train, X_test, y_train, y_test = train_test_split(data[['x1', 'x2', 'x3']], data['y'], test_size=0.2, random_state=0)
# สร้างโมเดล Linear Regression
model = LinearRegression()
# Train โมเดลด้วย train set
model.fit(X_train, y_train)
# ทำนายผลโดยใช้ test set
y_pred = model.predict(X_test)
# คำนวณค่า Mean Squared Error และ R2 score
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# แสดงผลลัพธ์
print('Coefficients: ', model.coef_)
print('Mean Squared Error: ', mse)
print('R2 score: ', r2)
# พล็อตกราฟ
plt.scatter(y_test, y_pred)
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.title('Multiple Regression')
plt.show()ผลลัพธ์ที่ได้ คือ
Coefficients: [ 2.01020764 3.01932389 -3.99529095]
Mean Squared Error: 10.343873195094478
R2 score: 0.9826132961120326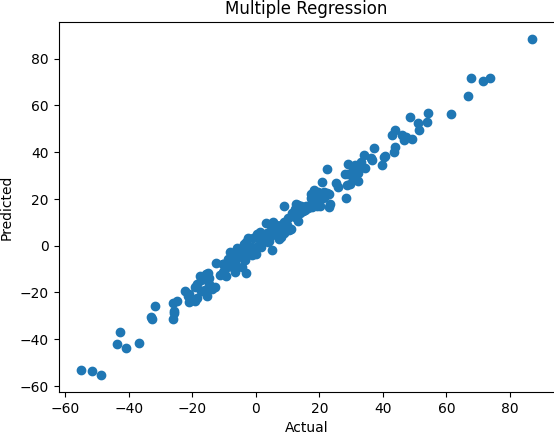
จากตัวอย่างดังกล่าว จะมีการแบ่งข้อมูลเป็น train set และ test set ด้วยฟังก์ชัน train_test_split โดยกำหนด test size เป็น 0.2 ซึ่งหมายความว่า test set จะมีขนาด 20% ของข้อมูลทั้งหมด และกำหนด random state เพื่อให้ผลการแบ่งข้อมูลเหมือนกันทุกครั้งที่รันโค้ด
จากนั้นใช้โมเดล Linear Regression จาก sklearn.linear_model เพื่อสร้างโมเดล และ Train โมเดลด้วย train set โดยใช้เมธอด fit() สุดท้ายทำนายผลโดยใช้ test set และคำนวณค่า Mean Squared Error

