
K-nearest neighbors (KNN) คืออัลกอริทึมในการเรียนรู้แบบความเข้าใกล้ของข้อมูล (instance-based learning) ที่ใช้ในการจัดกลุ่ม (classification) หรือการทำนายค่า (regression) โดยใช้ข้อมูลที่มีอยู่แล้วในการทำนายผลลัพธ์ของข้อมูลใหม่ อัลกอริทึม KNN จะใช้วิธีการค้นหาข้อมูลที่มีความใกล้เคียงกับข้อมูลที่ต้องการจัดกลุ่ม โดยจะตรวจสอบจำนวน K รายการข้อมูลที่ใกล้ที่สุดจากข้อมูลเป้าหมาย แล้วให้คำตอบโดยใช้ค่าเฉลี่ยของค่าผลลัพธ์ของ K รายการนั้นๆ
สมมติว่า เรามีชุดข้อมูลของผู้ป่วยโรคหัวใจ ที่ประกอบด้วยตัวแปรต่างๆ เช่น อายุ, เพศ, ระดับความเสี่ยง, ความดันโลหิต ซึ่งแต่ละตัวแปรนั้นมีค่าต่างๆ โดยการใช้ KNN จะช่วยในการทำนายว่าผู้ป่วยคนนี้เป็นโรคหัวใจหรือไม่ โดยวิธีการทำงานของ KNN คือจะเรียงข้อมูลทั้งหมดในชุดข้อมูลตามค่าความใกล้เคียงกับผู้ป่วยนี้ แล้วดูว่ากี่คนจาก K คนที่ใกล้เคียงกับผู้ป่วยนี้มีโรคหัวใจ แล้วนำค่าเฉลี่ยของการเป็นโรคหัวใจของ K คนเหล่านั้น มาใช้ในการทำนายว่าผู้ป่วยคนนี้จะเป็นโรคหัวใจหรือไม่ เป็นต้น
K-nearest neighbors (KNN) เป็นอัลกอริทึมสำหรับ Supervised Learning ใช้ในการจัดกลุ่มของข้อมูล (classification) หรือคำนวณค่าของตัวแปรต่อเนื่อง (regression) โดยทำการหาข้อมูลที่ใกล้เคียงกับข้อมูลปัจจุบัน (current data) จากนั้นให้ค่าของตัวแปรเป้าหรือค่าที่ต้องการคำนวณจากข้อมูลที่ใกล้เคียงที่สุด (nearest neighbors)
วิธีการทำงานของ KNN คือในขั้นตอนการทดสอบ โดยการหาข้อมูลที่ใกล้เคียงกับข้อมูลปัจจุบัน โดยหาข้อมูลที่ใกล้เคียงกันโดยใช้วิธีการคำนวณระยะห่าง Euclidean distance หรือ Manhattan distance ระหว่างค่าของคุณสมบัติ (feature) ในข้อมูล และจากนั้นเลือกข้อมูลที่ใกล้เคียงกันที่สุด k ตัว โดย k เป็นตัวแปรที่กำหนดไว้ จากนั้นจะให้ค่าของตัวแปรเป้าหรือค่าที่ต้องการคำนวณจากตัวเลือก k ตัวนี้ เช่น หากต้องการจัดกลุ่มข้อมูลให้เป็น 2 กลุ่ม จะต้องกำหนด k=1 หรือ k=3 ก่อน จากนั้นคำนวณระยะห่างระหว่างข้อมูลทุกตัวกับข้อมูลปัจจุบันและเลือก k ตัวที่ใกล้เคียงกับข้อมูลปัจจุบันมากที่สุด แล้วนับจำนวนข้อมูลในแต่ละกลุ่มเพื่อกำหนดว่าข้อมูลปัจจุบันจะถูกจัดอยู่ในกลุ่มไหน
ตัวแปร k หมายถึง จำนวนของเพื่อนบ้าน (neighbors) ที่จะถูกใช้ในการคำนวณค่าของคลาส (class) ที่จะกำหนดให้กับข้อมูลที่เราต้องการจัดกลุ่ม ในกรณีที่ k=1 จะหมายถึงการใช้เพียงตัวอย่างเดียวเพื่อกำหนดคลาสของข้อมูลนั้น ๆ ในขณะที่ k>1 จะใช้จำนวนของเพื่อนบ้านมาเฉลี่ยกันเพื่อกำหนดคลาสของข้อมูล
การเลือกค่า k ที่เหมาะสมสำหรับโมเดล KNN จะต้องพิจารณาความซับซ้อนของข้อมูล และจำนวนของตัวอย่าง (samples) ที่มีอยู่ในชุดข้อมูล การเลือกค่า k ที่มากเกินไปอาจทำให้โมเดล overfitting และการเลือกค่า k ที่น้อยเกินไปอาจทำให้โมเดล underfitting
นอกจาก k แล้ว ยังมีตัวแปรอื่น ๆ เช่น การเลือก metric (ระยะทาง) ในการคำนวณระยะห่างระหว่างข้อมูล โดยที่ Euclidean distance เป็นตัวเลือกที่ได้รับความนิยมมากที่สุด แต่ยังมีตัวเลือกอื่น ๆ เช่น Manhattan distance, Minkowski distance ฯลฯ ที่สามารถเลือกใช้ได้ตามสถานการณ์และลักษณะของข้อมูล
K-nearest neighbors (KNN) เป็นอัลกอริทึมในกลุ่ม Supervised Learning ซึ่งใช้ในการจัดกลุ่มหรือแบ่งประเภทของข้อมูล โดยทำการหา k จำนวนตัวอย่างที่อยู่ใกล้ที่สุดกับตัวอย่างทดสอบ แล้วให้คลาสหรือป้ายกำกับของ k ตัวอย่างนั้นๆ เป็นคำตอบ
ขั้นตอนการใช้งาน KNN มีดังนี้
-
การเตรียมข้อมูล
ก่อนที่จะนำข้อมูลไปใช้ในการสร้างโมเดล KNN จำเป็นต้องทำการเตรียมข้อมูลให้เหมาะสมกับการใช้งาน โดยมักจะรวมถึงการแยกข้อมูลออกเป็น training set และ test set โดย training set จะถูกนำไปใช้ในการเทรนโมเดล KNN และ test set จะถูกนำไปใช้ในการทดสอบและประเมินประสิทธิภาพของโมเดล KNN -
การกำหนดพารามิเตอร์
ก่อนที่จะเริ่มต้นเทรนโมเดล KNN จำเป็นต้องกำหนดพารามิเตอร์ต่างๆ ซึ่งสามารถกำหนดได้เช่น จำนวน k หรือจำนวนตัวอย่างที่ใช้ในการทำนาย รวมถึงการกำหนดวิธีการคำนวณระยะทางหรือความคล้ายคลึงระหว่างตัวอย่าง -
การเทรนโมเดล
เมื่อได้กำหนดพารามิเตอร์ต่างๆ และทำการเตรียมข้อมูลเรียบร้อยแล้ว ต่อไปคือการสร้างโมเดล KNN โดยการเทรนโมเดลนั้นจะทำการค้นหาตัวอย่างที่ใกล้ที่สุดกับข้อมูลที่ต้องการจัดกลุ่ม โดยการค้นหานั้นจะใช้วิธีการคำนวณระยะทางหรือความคล้ายคลึงระหว่างตัวอย่างที่มีอยู่ใน training set กับตัวอย่างที่ต้องการจัดกลุ่ม -
การทำนาย
เมื่อได้เทรนโมเดลและนำข้อมูล test set มาใช้ในการทดสอบโมเดล KNN จะทำการหา k ตัวอย่างที่ใกล้ที่สุดกับข้อมูล test และจะให้ข้อมูล test นั้นอยู่ในกลุ่มเดียวกับตัวอย่างที่มีจำนวนมากที่สุด -
การประเมินผล
เมื่อได้ทำการทดสอบโมเดลแล้วจะต้องทำการประเมินผลโมเดลว่ามีประสิทธิภาพดีหรือไม่ โดยการประเมินผลนั้นสามารถทำได้หลายวิธี เช่น การใช้ confusion matrix เพื่อวัดประสิทธิภาพของโมเดลในการทำนายคลาสต่างๆ หรือการคำนวณค่า accuracy, precision, recall, F1 score เป็นต้น
การใช้งาน K-nearest neighbors (KNN) ใน Machine Learning ด้วย Python จำเป็นต้องใช้ Library ชื่อว่า scikit-learn ซึ่งเป็น Library สำหรับ Machine Learning ที่รวบรวม Algorithm ต่างๆ ไว้เป็น Package ที่สามารถ Import เข้ามาใช้งานได้ง่าย
ตัวอย่าง การใช้งาน K-nearest neighbors (KNN) ใน Python ด้วย scikit-learn มีดังนี้
# Import Library และโหลดข้อมูล
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
# ขั้นตอนที่ 1 แบ่งข้อมูลออกเป็น training set และ test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ขั้นตอนที่ 2 กำหนดพารามิเตอร์ k และสร้างโมเดล KNN
from sklearn.neighbors import KNeighborsClassifier
k = 3
knn = KNeighborsClassifier(n_neighbors=k)
# ขั้นตอนที่ 3 เทรนโมเดล KNN ด้วย training set
knn.fit(X_train, y_train)
# ขั้นตอนที่ 4 ใช้โมเดล KNN ในการทำนายผลลัพธ์จาก test set
y_pred = knn.predict(X_test)
# ขั้นตอนที่ 5 ประเมินผลลัพธ์การทำนาย
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)ผลลัพธ์ที่ได้ คือ
Accuracy: 1.0ตัวอย่าง การเขียน Python ใช้ K-nearest neighbors (KNN) ใน Machine Learning ด้วยการ Import NumPy และ Scikit-learn library โดยสามารถแยกเขียนให้เห็นเป็นขั้นตอนได้ดังนี้
import numpy as np
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=100, centers=2, n_features=2, random_state=42)โดยที่ n_samples คือจำนวนตัวอย่างทั้งหมดที่ต้องการสร้าง, centers คือจำนวนกลุ่มของข้อมูล, n_features คือจำนวนตัวแปรในแต่ละตัวอย่าง, และ random_state คือการกำหนดสถานะสุ่มในการสร้างข้อมูล
ต่อมาเราสามารถสร้างโมเดล KNN ด้วย Scikit-learn library ดังนี้
from sklearn.neighbors import KNeighborsClassifier
k = 5
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X, y)โดยที่ k คือจำนวนเพื่อนบ้านที่ใช้ในการทำนาย
หลังจากนั้นเราสามารถใช้โมเดล KNN ที่เราสร้างมาเพื่อทำนายคลาสของตัวอย่างใหม่ด้วยฟังก์ชั่น predict() ดังนี้
X_new = np.array([[0, 0], [6, 6]])
y_pred = knn.predict(X_new)
print(y_pred)โดยที่ X_new คือตัวอย่างใหม่ที่เราต้องการทำนายคลาส, และ y_pred คือผลลัพธ์จากการทำนายคลาสของตัวอย่างใหม่
สุดท้ายเราสามารถใช้ Matplotlib library เพื่อวาดกราฟเพื่อแสดงผลลัพธ์การทำนายของโมเดล KNN ดังนี้
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.scatter(X_new[:, 0], X_new[:, 1], c=y_pred, marker='s', s=100)
plt.show()โดยที่ X[:, 0] และ X[:, 1] คือข้อมูลในแกน x และ y ของข้อมูลเดิมที่เราสร้างขึ้น, c=y คือการกำหนดสีของแต่ละคลาส
ผลลัพธ์ที่ได้ คือ

จากตัวอย่าง เริ่มต้นจากการสร้าง dataset ด้วยฟังก์ชัน make_blobs() ที่ให้คำสั่งในการสร้างจุดข้อมูลขึ้นมา โดยกำหนดพารามิเตอร์ดังนี้
- n_samples: จำนวนจุดข้อมูลทั้งหมดใน dataset
- centers: จำนวน cluster หรือกลุ่มของจุดข้อมูลที่ต้องการสร้าง
- random_state: สุ่มเลขเพื่อให้การสุ่มเป็น deterministic หรือไม่สุ่มซ้ำกัน
ต่อมาก็ทำการแบ่ง dataset เป็น train set และ test set โดยใช้ฟังก์ชัน train_test_split() จาก scikit-learn ดังนี้
- test_size: สัดส่วนของจำนวนจุดข้อมูลที่จะเอาไปใช้ใน test set
- random_state: สุ่มเลขเพื่อให้การสุ่มเป็น deterministic หรือไม่สุ่มซ้ำกัน
จากนั้นก็ทำการเทรนโมเดล KNN โดยใช้ฟังก์ชัน KNeighborsClassifier() จาก scikit-learn ดังนี้
- n_neighbors: จำนวน k ใน KNN
- weights: วิธีการคำนวณน้ำหนักในการหาค่าเฉลี่ยของ k ตัวอย่างเช่น uniform (น้ำหนักเท่ากัน) หรือ distance (น้ำหนักตามระยะทาง)
- fit(X_train, y_train): ใช้ข้อมูล X_train, y_train เพื่อเทรนโมเดล
จากนั้นก็ทำการทดสอบโมเดลด้วย test set โดยใช้ฟังก์ชัน predict() ดังนี้
- predict(X_test): ใช้โมเดลที่เทรนไว้กับ X_train, y_train เพื่อทำนายคลาสของจุดข้อมูลใน X_test
สุดท้ายก็ใช้งาน matplotlib เพื่อสร้างกราฟ scatter plot ข้อมูล
ตัวอย่าง การใช้ K-nearest neighbors (KNN) แบบ 4 กลุ่ม และสร้างกราฟ matplotlib แยกสีในแต่ละกลุ่ม
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# สร้าง dataset ขึ้นมา
X = np.concatenate((np.random.randn(50, 2) * 0.4 + [1.5, 1.5],
np.random.randn(50, 2) * 0.4 + [-1.5, 1.5],
np.random.randn(50, 2) * 0.4 + [1.5, -1.5],
np.random.randn(50, 2) * 0.4 + [-1.5, -1.5]))
y = np.concatenate((np.zeros(50), np.ones(50), np.ones(50) * 2, np.ones(50) * 3))
# แบ่ง train set และ test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# สร้าง model K-nearest neighbors (KNN)
k = 5
clf = KNeighborsClassifier(k, metric='euclidean')
clf.fit(X_train, y_train)
# ทำนายค่า y จาก X_test
y_pred = clf.predict(X_test)
# คำนวณค่าความแม่นยำ
acc = accuracy_score(y_test, y_pred)
print(f"Accuracy: {acc:.2f}")
# กำหนด colormap สำหรับ plot
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF', '#FFA500'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF', '#FF8C00'])
# plot decision boundary และแยกสีแต่ละกลุ่ม
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolor='k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title(f"KNN (k={k}, Accuracy={acc:.2f})")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()ผลลัพธ์ที่ได้ คือ
Accuracy: 1.00
จากตัวอย่าง มีการสร้าง dataset มี 4 กลุ่ม และนำมาใช้ K-nearest neighbors (KNN) เพื่อแบ่งกลุ่มของข้อมูล โดยมีขั้นตอนดังนี้
- import library ที่จำเป็น (numpy, matplotlib, sklearn)
- สร้าง dataset ขึ้นมาโดยใช้ np.concatenate() เพื่อรวม array ของ numpy ที่สร้างด้วย np.random.randn() และเลือกจุดศูนย์กลาง (mean) ของแต่ละกลุ่ม เก็บไว้ในตัวแปร X และ y โดย X เป็น feature ของ dataset และ y เป็น target variable
- แบ่ง dataset เป็น train set และ test set ด้วยฟังก์ชัน train_test_split() โดยกำหนด test_size=0.3 และ random_state=42
- สร้าง model K-nearest neighbors (KNN) ด้วยคลาส KNeighborsClassifier() และกำหนดค่า k=5 และ metric=’euclidean’ เพื่อใช้ Euclidean distance เป็น metric ในการคำนวณระยะทางระหว่างจุด
- สอนโมเดลด้วยข้อมูล train set ด้วยฟังก์ชัน fit()
- ทำนายค่า y จากข้อมูล test set ด้วยฟังก์ชัน predict()
- คำนวณค่าความแม่นยำของโมเดลด้วยฟังก์ชัน accuracy_score()
- กำหนด colormap สำหรับการ plot โดยใช้ฟังก์ชัน ListedColormap()
- สร้างกราฟ decision boundary และแยกสีแต่ละกลุ่มด้วยฟังก์ชัน pcolormesh(), scatter() และ xlim(), ylim() เพื่อกำหนดขอบเขตของกราฟ และกำหนดค่า title, xlabel, ylabel ของกราฟ และแสดงกราฟด้วยฟังก์ชัน show()
ตัวอย่าง การใช้ K-nearest neighbors (KNN) และสร้างกราฟ matplotlib แยกสีในแต่ละกลุ่มเป็น 3 กลุ่ม เกี่ยวกับการขายสินค้า เขียนโค้ด Python ได้ดังนี้
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# สร้าง dataset ขึ้นมา
np.random.seed(42)
# กลุ่มสินค้าที่ขายดี
group1 = np.random.randn(50, 2) * 0.4 + [2, 2]
# กลุ่มสินค้าที่ขายไม่ได้
group2 = np.random.randn(50, 2) * 0.4 + [0, 0]
# กลุ่มสินค้าที่ขายได้น้อย
group3 = np.random.randn(50, 2) * 0.4 + [-2, -2]
X = np.concatenate((group1, group2, group3))
y = np.concatenate((np.zeros(50), np.ones(50), np.ones(50)*2))
# แบ่ง train set และ test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# สร้าง model K-nearest neighbors (KNN)
k = 5
clf = KNeighborsClassifier(k, metric='euclidean')
clf.fit(X_train, y_train)
# ทำนายค่า y จาก X_test
y_pred = clf.predict(X_test)
# คำนวณค่าความแม่นยำ
acc = accuracy_score(y_test, y_pred)
print(f"Accuracy: {acc:.2f}")
# กำหนด colormap สำหรับ plot
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
# plot decision boundary และแยกสีแต่ละกลุ่ม
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolor='k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title(f"KNN (k={k}, Accuracy={acc:.2f})")
plt.xlabel("Sales Performance")
plt.ylabel("Marketing Effectiveness")
plt.show()ผลลัพธ์ที่ได้ คือ
Accuracy: 1.00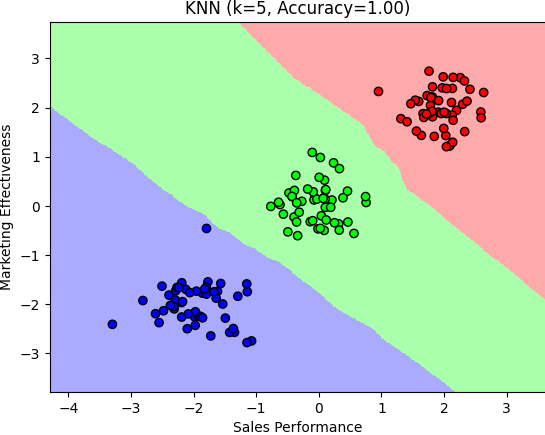
จากตัวอย่าง เป็นการใช้ K-nearest neighbors (KNN) ในการแยกกลุ่มของสินค้าที่ขายดี สินค้าที่ขายไม่ได้ และสินค้าที่ขายได้น้อย โดยมีการสร้าง dataset ขึ้นมาโดยใช้ฟังก์ชัน np.random.randn และการกำหนดตำแหน่งของแต่ละกลุ่มสินค้า และทำการเชื่อมต่อกันด้วย np.concatenate
จากนั้นทำการแบ่ง train set และ test set โดยใช้ฟังก์ชัน train_test_split จากนั้นสร้าง model K-nearest neighbors (KNN) โดยกำหนดค่า k เท่ากับ 5 และ metric เท่ากับ ‘euclidean’ และทำการ fit model ด้วย train set จากนั้นทำการทำนายค่า y จาก test set และคำนวณค่าความแม่นยำโดยใช้ฟังก์ชัน accuracy_score
ในตัวอย่างมีการสร้าง dataset แบบสุ่มขึ้นมา 3 กลุ่ม โดยแต่ละกลุ่มเป็นตำแหน่งของสินค้าที่ขายดี, สินค้าที่ขายไม่ได้ และสินค้าที่ขายได้น้อย โดยกำหนดค่า mean และ standard deviation ของแต่ละกลุ่ม
จากนั้น ใช้โมดูล train_test_split เพื่อแบ่งข้อมูลเป็น train set และ test set โดย test set จะมีขนาด 30% ของข้อมูลทั้งหมด
เมื่อแบ่งข้อมูลเสร็จแล้ว สร้างโมเดล K-nearest neighbors (KNN) ด้วยค่า k = 5 และใช้ Euclidean distance เป็น metric ในการคำนวณระยะห่าง
หลังจากสร้างโมเดล KNN เสร็จสิ้น ทำการทดสอบโมเดลด้วย test set และคำนวณค่า accuracy ของโมเดล
สุดท้าย ทำการ plot กราฟ decision boundary ของโมเดล KNN โดยใช้ colormap สำหรับแยกสีแต่ละกลุ่ม และแสดงผลลัพธ์ในกราฟที่แสดง Sales Performance กับ Marketing Effectiveness บนแกน x และ y ตามลำดับ สำหรับการแสดงผลข้อมูล โค้ดจะทำการกำหนด colormap สำหรับ plot และ plot decision boundary และแยกสีแต่ละกลุ่ม โดยใช้ฟังก์ชัน pcolormesh เพื่อแสดงผล decision boundary และใช้ฟังก์ชัน scatter เพื่อแสดงผลข้อมูลแต่ละจุดใน dataset และทำการแยกสีแต่ละกลุ่มด้วย cmap_bold จากนั้นกำหนด title, xlabel, และ ylabel และแสดงผลโดยใช้ฟังก์ชัน show() ของ matplotlib.pyplot

