
Hierarchical Clustering เป็นเทคนิคในการแบ่งกลุ่มข้อมูล (Clustering) ที่ใช้วิธีการสร้างความสัมพันธ์ระหว่างข้อมูลจากการจัดเรียงตามระยะห่างระหว่างข้อมูล ซึ่งการจัดเรียงนี้จะมีการสร้างโครงสร้างเป็นต้นไม้ (Tree-like Structure) ที่เรียกว่า Dendrogram เพื่อแสดงความสัมพันธ์ระหว่างกลุ่มข้อมูล
วิธีการทำงานของ Hierarchical Clustering จะเริ่มต้นด้วยการกำหนดระยะห่างระหว่างข้อมูล ซึ่งจะมีหลายวิธีในการคำนวณ เช่น Euclidean distance, Manhattan distance, หรือ Cosine similarity แล้วจะนำค่าระยะห่างระหว่างข้อมูลมาใช้ในการจัดเรียงตามระดับความสัมพันธ์ระหว่างกลุ่มข้อมูล โดยเริ่มจากการสร้างกลุ่มข้อมูลเป็นกลุ่มเดียวกันแล้ววนลูปเพื่อรวมกลุ่มข้อมูลเข้าด้วยกัน จนกระทั่งมีการจัดเรียงข้อมูลเป็นกลุ่มเดียวกัน
Hierarchical Clustering แบ่งออกเป็น 2 ประเภท คือ
-
Agglomerative (Bottom-up) Hierarchical Clustering เริ่มจากวิเคราะห์ข้อมูลในแต่ละจุดแยกจากกันเป็น cluster เล็กๆ ก่อน จากนั้นจะรวม cluster เหล่านี้เข้าด้วยกันเป็น cluster ใหญ่ๆ โดยมีวิธีการรวม cluster ที่หลากหลาย เช่น การรวม cluster ที่อยู่ใกล้เคียงกันที่สุด หรือการรวม cluster ที่มีขนาดเล็กๆ ก่อน แล้วจึงรวมเข้าด้วยกันเป็น cluster ใหญ่ๆ ทีละขั้นตอนจนกระทั่งได้ cluster เดียวที่มีข้อมูลทั้งหมด
-
Divisive (Top-down) Hierarchical Clustering เริ่มจากที่มี cluster ใหญ่ๆ ทั้งหมดอยู่เดียวกัน แล้วแยก cluster ออกเป็น cluster เล็กๆ ตามลำดับ จนกระทั่งแยกเป็น cluster ที่มีข้อมูลแต่ละจุดเพียงคนละตัวเท่านั้น
ขั้นตอนการแบ่งกลุ่มโดยใช้ Hierarchical Clustering มีดังนี้
-
นำข้อมูลมาตรวจสอบและเตรียมข้อมูล
- ตรวจสอบความสมบูรณ์และความถูกต้องของข้อมูล
- ปรับข้อมูลให้เป็นรูปแบบที่เหมาะสมสำหรับการแบ่งกลุ่ม
- แยกข้อมูลออกเป็นชุด train set และ test set
-
กำหนดวิธีการคำนวณความคล้ายคลึง (similarity/distance measure) ระหว่างข้อมูล
- มีหลายวิธีในการคำนวณความคล้ายคลึง เช่น Euclidean distance, Manhattan distance, Cosine similarity เป็นต้น
- การเลือกวิธีนี้จะขึ้นอยู่กับลักษณะของข้อมูลและวัตถุประสงค์ของการแบ่งกลุ่ม
-
สร้าง dendrogram
- ใช้ข้อมูลและความคล้ายคลึงของข้อมูลในการสร้าง dendrogram ซึ่งเป็นตัวแทนของโมเดลการแบ่งกลุ่ม
- Dendrogram คือแผนภูมิที่แสดงความคล้ายคลึงระหว่างข้อมูลทุกคู่ของข้อมูลทั้งหมด โดยที่แต่ละจุดบนเส้นเเกน Y แทนข้อมูล และเส้นเชื่อมระหว่างจุดบนเส้นเเกน Y แสดงความคล้ายคลึงของข้อมูลระหว่างกัน
-
กำหนดจำนวนกลุ่ม
- จาก dendrogram สามารถกำหนดจำนวนกลุ่มที่เหมาะสมได้โดยการตัด dendrogram ด้วยเส้นตัด (cutting line) ให้ได้จำนวนกลุ่มที่เหมาะสม
-
สร้างโมเดลและแบ่งกลุ่มข้อมูล
-
เลือก algorithm ที่ต้องการใช้ในการ clustering เช่น k-means, hierarchical clustering, DBSCAN เป็นต้น
-
กำหนดค่า hyperparameters ของ algorithm ที่เราเลือก เช่น จำนวน cluster ในกรณีของ k-means, threshold distance ในกรณีของ hierarchical clustering เป็นต้น
-
นำข้อมูลที่เราต้องการแบ่งกลุ่มมาสร้าง model
-
สร้างกลุ่มของข้อมูลด้วย algorithm ที่เราเลือก โดยใช้ hyperparameters ที่กำหนดไว้ และข้อมูลที่ส่งเข้ามาใน model
-
ประเมินผลและวิเคราะห์ cluster ที่ได้จากโมเดล เช่น ดูว่า cluster มีความสัมพันธ์กันอย่างไร หรือ cluster มีความแตกต่างกันอย่างไร
-
ปรับแต่ง model หรือ hyperparameters ตามผลการประเมินและวิเคราะห์ เพื่อให้ model แบ่งกลุ่มข้อมูลได้อย่างเหมาะสม
-
นำ model ที่ปรับแต่งเรียบร้อยแล้วไปใช้งานจริงในการแบ่งกลุ่มข้อมูล
-
- สร้าง dendrogram ขึ้นมา เพื่อใช้ในการหาค่า k (จำนวนกลุ่ม) ที่เหมาะสม โดย dendrogram จะแสดงความสัมพันธ์ระหว่างข้อมูลในรูปแบบของต้นไม้ โดยแกน x จะแสดงจำนวนของข้อมูลแต่ละกลุ่ม และแกน y จะแสดงค่าความคล้ายคลึงระหว่างกลุ่ม โดยค่าความคล้ายคลึงจะมีค่ามากที่สุดที่สามารถเรียกว่าเป็นสายแบ่ง (dendrogram cut) ได้และจะกำหนดจำนวนกลุ่มตามจำนวนสายแบ่งที่เลือกได้
การใช้ Hierarchical Clustering ในการจัดกลุ่มข้อมูลที่เกี่ยวกับการแบ่งกลุ่มคล้ายคลึงกันแล้ว ยังสามารถนำมาประยุกต์ใช้ในงานอื่นๆ ได้ ตัวอย่างเช่น
-
การจัดกลุ่มลูกค้า (Customer Segmentation) – โดยใช้ข้อมูลเกี่ยวกับลูกค้า เช่น วงเงินที่ใช้ในการซื้อสินค้า การเข้าชมเว็บไซต์ หรือแบบสอบถามเพื่อแบ่งกลุ่มลูกค้าที่มีความสนใจในสินค้าและบริการเดียวกัน เพื่อสามารถสร้างกลยุทธ์การตลาดและการขายได้อย่างมีประสิทธิภาพ
-
การจัดกลุ่มภาพถ่าย (Image Segmentation) – โดยใช้ข้อมูลภาพถ่าย เช่น การจัดกลุ่มและจำแนกภาพถ่ายของมนุษย์ สัตว์ หรือวัตถุ เพื่อใช้ในการสร้างซอฟต์แวร์ระบบควบคุมหุ่นยนต์ การตรวจสอบความปลอดภัย หรือการตรวจจับวัตถุในอุตสาหกรรม
-
การจัดกลุ่มเอกสาร (Document Clustering) – โดยใช้ข้อมูลของเอกสาร เช่น บทความ หรือเอกสารต่างๆ เพื่อจัดกลุ่มเอกสารที่มีเนื้อหาที่คล้ายกัน เพื่อใช้ในการวิเคราะห์เนื้อหา หรือสร้างระบบค้นหาข้อมูลที่มีประสิทธิภาพ
-
การจัดกลุ่มภาษา (Language Clustering) – โดยใช้ข้อมูลของภาษา เช่น คำ ประโยค หรือเอกสารต่างๆ เพื่อจัดกลุ่มภาษาที่มีความสัมพันธ์กัน เพื่อใช้ในการสร้างระบบแปลภาษาหรือระบบจดจำคำพูด
-
การจัดการทรัพยากรระบบคอมพิวเตอร์ (Computer Resource Clustering) – การจัดกลุ่มคอมพิวเตอร์หรือเครื่องมือที่ใช้งานเพื่อจัดการทรัพยากรเครือข่าย เช่น การจัดกลุ่มเครื่องพิมพ์หรือเครื่องคอมพิวเตอร์ต่างๆ เพื่อสะท้อนถึงพฤติกรรมการใช้งานและตรวจสอบปัญหาที่อาจเกิดขึ้น
- การจัดกลุ่มสินค้า (Product Clustering) – การจัดกลุ่มสินค้าต่างๆ โดยพิจารณาคุณสมบัติของสินค้า เช่น ราคา, แบรนด์, สี, ขนาด เป็นต้น ที่สามารถนำมาใช้ในการจัดการสินค้าให้เหมาะสม
-
การตลาด (Market Clustering) – การจัดกลุ่มลูกค้าที่มีความต้องการหรือความสนใจคล้ายกัน เพื่อนำข้อมูลเหล่านี้ไปใช้ในการวางแผนการตลาด หรือใช้ในการส่งเสริมการขาย การวิเคราะห์การจัดกลุ่มลูกค้ายังช่วยให้สามารถจัดทีมขายและกลยุทธ์การตลาดได้อย่างมีประสิทธิภาพ
-
การวิเคราะห์ข้อมูลสุขภาพ (Health Analysis Clustering) – การจัดกลุ่มผู้ป่วยที่มีภาวะโรคคล้ายกัน เพื่อนำข้อมูลเหล่านี้ไปใช้ในการวิเคราะห์ข้อมูลสุขภาพและวิจัยทางการแพทย์ อาทิเช่นการวิเคราะห์โรคร้ายแรงหรือการวิเคราะห์ปัจจัยเสี่ยงต่อโรคที่ส่งผลต่อสุขภาพ
อีกหนึ่งตัวอย่างการใช้ Hierarchical Clustering อในการจัดกลุ่มลูกค้า (Customer Segmentation) ของธุรกิจ เช่น สามารถนำข้อมูลการซื้อสินค้าของลูกค้า เช่น ประเภทสินค้า จำนวนการซื้อ ราคาเฉลี่ยต่อการซื้อ และอื่นๆ เพื่อแบ่งกลุ่มลูกค้าที่มีพฤติกรรมการซื้อคล้ายคลึงกัน เพื่อนำไปใช้ในการวางแผนการขาย โปรโมชั่นสินค้า หรือการสร้างสินค้าใหม่ที่เหมาะสมกับลูกค้าในแต่ละกลุ่มให้เหมาะสม และเพิ่มโอกาสในการขายสินค้าให้สูงสุดในแต่ละกลุ่มลูกค้านั้นๆ
ตัวอย่าง การจัดกลุ่มลูกค้าจะใช้ข้อมูลเชิงพหุคณิตเป็นหลัก เช่น รายได้ของลูกค้า จำนวนครั้งที่เข้าร้านค้า จำนวนสินค้าที่ซื้อ เป็นต้น ในตัวอย่างนี้เราจะใช้ข้อมูลจำลองที่เป็นตารางข้อมูลของลูกค้าที่มีรายได้และจำนวนครั้งที่เข้าร้านค้าดังนี้
| รายได้ (หน่วย: บาท) | จำนวนครั้งที่เข้าร้านค้า |
|---|---|
| 10000 | 2 |
| 20000 | 4 |
| 15000 | 2 |
| 8000 | 1 |
| 30000 | 6 |
| 12000 | 3 |
| 5000 | 1 |
| 25000 | 5 |
| 18000 | 4 |
| 1000 | 1 |
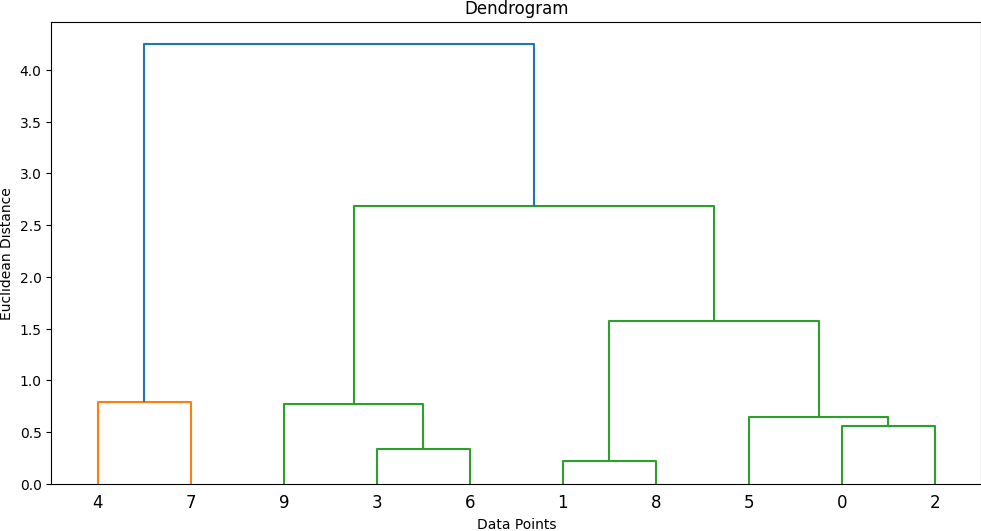
สามารถเขียนโค้ด Pythone ได้ดังนี้
import pandas as pd
import numpy as np
from scipy.cluster.hierarchy import dendrogram, linkage
from matplotlib import pyplot as plt
data = pd.DataFrame({
'income': [10000, 20000, 15000, 8000, 30000, 12000, 5000, 25000, 18000, 1000],
'visits': [2, 4, 2, 1, 6, 3, 1, 5, 4, 1]
})
data_standardized = data.apply(lambda x: (x - x.mean()) / x.std(), axis=0)
Z = linkage(data_standardized, method='complete', metric='euclidean')
plt.figure(figsize=(12,6))
dendrogram(Z)
plt.title('Dendrogram')
plt.xlabel('Data Points')
plt.ylabel('Euclidean Distance')
plt.show()ผลลัพธ์ที่ได้ คือ
ตัวอย่าง การใช้ Hierarchical Clustering เกี่ยวกับการจัดกลุ่มสินค้า
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
data = pd.DataFrame({
'product': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'],
'price': [25, 30, 35, 20, 40, 50, 10, 5, 15, 45],
'rating': [4.3, 4.5, 4.1, 4.0, 4.8, 4.7, 3.9, 3.5, 4.0, 4.9],
'sales': [100, 150, 200, 75, 300, 400, 50, 20, 70, 500]
})
Z = linkage(data[['price', 'rating', 'sales']], method='complete', metric='euclidean')
plt.figure(figsize=(10, 5))
dendrogram(Z)
plt.show()ผลลัพธ์ที่ได้ คือ

จากตัวอย่าง ได้ใช้ Hierarchical Clustering เพื่อจัดกลุ่มสินค้าโดยใช้ข้อมูลราคา (price), คะแนนโดยเฉลี่ย (rating) และยอดขาย (sales) ของสินค้าทั้ง 10 รายการ (A-J) ซึ่งเก็บอยู่ใน DataFrame ชื่อ data
โดยใช้ฟังก์ชัน linkage() ของ scipy.cluster.hierarchy เพื่อคำนวณระยะห่างระหว่างแต่ละกลุ่มสินค้า โดยกำหนดวิธีการคำนวณความคล้ายคลึงเป็น Complete linkage และคำนวณด้วย Euclidean distance
เมื่อได้ระยะห่างระหว่างกลุ่มสินค้าแล้ว จะนำมาสร้าง dendrogram โดยใช้ฟังก์ชัน dendrogram() ของ matplotlib.pyplot
สีที่ปรากฏใน dendrogram แสดงถึงการจัดกลุ่มที่แตกต่างกันของข้อมูล ซึ่งเส้นสีส้มแสดงถึงการจัดกลุ่มที่สูงสุด (การแบ่งกลุ่มที่เป็นไปได้มากที่สุด) ที่สามารถทำได้โดยไม่เกินจำนวนกลุ่มที่กำหนดไว้ ในขณะที่เส้นสีเขียวแสดงถึงการจัดกลุ่มที่เกิดขึ้นระหว่างการแบ่งกลุ่มในแต่ละระดับของ dendrogram โดยการแบ่งกลุ่มที่เกิดขึ้นในแต่ละระดับจะน้อยลงตามการเลือกตัวแบ่งของ hierarchical clustering ในแต่ละรอบของการจัดกลุ่ม
จัดกลุ่มสินค้าจากข้อมูล 4 คอลัมน์คือ price, rating, sales และ product โดยใช้วิธี complete linkage และ Euclidean distance ในการคำนวณความคล้ายคลึงระหว่างสินค้า จากนั้นใช้ฟังก์ชัน dendrogram เพื่อแสดงผลของการจัดกลุ่มในรูปแบบของ dendrogram โดยแกน x คือ ชื่อสินค้า และแกน y คือค่าความคล้ายคลึงระหว่างสินค้าที่ถูกคำนวณจาก Z โดย Z เป็น output ของฟังก์ชัน linkage ที่รับข้อมูลเป็นตาราง data และระบุวิธีและวิธีคำนวณค่าคล้ายคลึงด้วย method และ metric ตามลำดับ
ผลลัพธ์ที่ได้จากการรันโค้ดนี้คือ การแสดง dendrogram ของกลุ่มสินค้าที่ได้จัดกลุ่มโดยใช้ Hierarchical Clustering โดยแกน x คือสินค้าแต่ละรายการ (A-J) และแกน y คือระยะห่างระหว่างกลุ่มสินค้า โดยสีของเส้นใน dendrogram แสดงถึงระยะห่างระหว่างกลุ่มสินค้า โดยสีเข้มจะแสดงถึงความคล้ายคลึงระหว่างกลุ่มสินค้าที่มีระยะห่างน้อย ส่วนสีอ่อนจะแสดงถึงกลุ่มสินค้าที่มีระยะห่างมากกว่า
ตัวอย่าง การใช้ Hierarchical Clustering เพื่อจัดกลุ่มลูกค้าที่มีความคล้ายคลึงกันเป็นกลุ่มเดียวกัน เพื่อใช้ในการพัฒนากลยุทธ์การตลาดในอนาคต โดยใช้ข้อมูลต่างๆ เช่น ข้อมูลลูกค้า เช่น อายุ รายได้ ประเภทสินค้าที่สนใจ ปริมาณการซื้อสินค้า เป็นต้น
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
data = pd.DataFrame({
'age': [20, 22, 25, 26, 28, 30, 32, 34, 36, 38, 40, 42, 45, 48, 50],
'income': [20000, 22000, 24000, 28000, 30000, 32000, 34000, 36000, 38000, 40000, 42000, 44000, 46000, 48000, 50000],
'product_type': ['A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E', 'A', 'B', 'C', 'D', 'E'],
'purchase_amount': [50, 75, 100, 125, 150, 50, 75, 100, 125, 150, 50, 75, 100, 125, 150]
})
Z = linkage(data[['age', 'income', 'purchase_amount']], method='average', metric='euclidean')
plt.figure(figsize=(10, 5))
dendrogram(Z)
plt.show()ผลลัพธ์ที่ได้ คือ

จากตัวอย่าง เป็นการทำ Hierarchical Clustering ของข้อมูลเกี่ยวกับการตลาด โดยมีตัวแปรใน DataFrame ที่ใช้ในการทำ clustering ประกอบด้วย ‘age’ (อายุ), ‘income’ (รายได้), ‘product_type’ (ประเภทสินค้า), และ ‘purchase_amount’ (จำนวนที่ซื้อสินค้า) โดยใช้ linkage() function ด้วยวิธีการคำนวณความคล้ายคลึงแบบ average linkage และคำนวณความคล้ายคลึงด้วย Euclidean distance จากนั้น plot dendrogram ของการ clustering ด้วย dendrogram() function และ matplotlib.pyplot โดยสีของเส้นบน dendrogram แสดงถึงความคล้ายคลึงระหว่างกลุ่ม โดยสีเขียวแสดงถึงกลุ่มสินค้า A และ B และสีส้มแสดงถึงกลุ่มสินค้า C, D และ E โดยสามารถตัด dendrogram เพื่อเลือกจำนวนกลุ่มที่เหมาะสมได้
จัดกลุ่มลูกค้าในการตลาด จะเห็นได้ว่าเราสามารถแบ่งกลุ่มลูกค้าตามลักษณะการซื้อสินค้าได้ โดยแบ่งเป็น 5 กลุ่มตามเส้นแบ่งและสีใน Dendrogram ซึ่งแต่ละกลุ่มสามารถอธิบายได้ดังนี้
- กลุ่มที่ 1 คือ ลูกค้าที่มีอายุต่ำกว่า 30 ปี และมียอดรายได้ต่ำกว่า 30,000 บาท และซื้อสินค้าจำนวนน้อยกว่า 100 บาท
- กลุ่มที่ 2 คือ ลูกค้าที่มีอายุต่ำกว่า 30 ปี แต่มียอดรายได้สูงกว่า 30,000 บาท และซื้อสินค้าจำนวนน้อยกว่า 100 บาท
- กลุ่มที่ 3 คือ ลูกค้าที่มีอายุระหว่าง 30-40 ปี และมียอดรายได้ระหว่าง 30,000-40,000 บาท และซื้อสินค้าจำนวนน้อยกว่า 100 บาท
- กลุ่มที่ 4 คือ ลูกค้าที่มีอายุระหว่าง 30-40 ปี และมียอดรายได้สูงกว่า 40,000 บาท และซื้อสินค้าในปริมาณมากกว่ากลุ่มอื่น
- กลุ่มที่ 5 คือ ลูกค้าที่มีอายุสูงกว่า 40 ปี และมียอดรายได้สูงกว่า 40,000 บาท และซื้อสินค้าในปริมาณมากกว่ากลุ่มอื่น

