
การแจกแจงข้อมูล (Data Distribution) เป็นการวิเคราะห์และแสดงผลการกระจายของข้อมูลในชุดข้อมูล โดยที่จะต้องดูความถี่ของค่าต่างๆ และว่าข้อมูลกระจายอย่างไรในช่วงต่างๆ ของชุดข้อมูลนั้นๆ
การแจกแจงข้อมูลเป็นส่วนสำคัญในการวิเคราะห์ข้อมูล โดยเฉพาะอย่างยิ่งในการสร้างและประเมินโมเดล Machine Learning เพราะสามารถช่วยในการเลือกและปรับแต่งโมเดลได้ดีขึ้น โดยการวิเคราะห์การแจกแจงข้อมูลจะช่วยให้เราเข้าใจลักษณะของข้อมูลและคุณสมบัติต่างๆ เช่น ความเป็นไปได้ของข้อมูล การกระจายของข้อมูล และการกำหนดขอบเขตของข้อมูล ซึ่งทั้งหมดนี้จะช่วยให้เราสามารถเลือกและปรับแต่งโมเดลให้เหมาะสมกับข้อมูลได้อย่างถูกต้อง
ยังมีหลายวิธีที่ใช้ในการแจกแจงข้อมูล เช่น การใช้ Histogram, Box Plot, Probability Density Function (PDF), Cumulative Density Function (CDF), และอื่นๆ ซึ่งแต่ละวิธีจะมีความเหมาะสมต่อการใช้งานต่างกันขึ้นอยู่กับลักษณะของข้อมูลและวัตถุประสงค์ของการวิเคราะห์
การแจกแจงข้อมูล (Data Distribution) ใน Machine Learning เป็นขั้นตอนการวิเคราะห์และประมวลผลข้อมูลเพื่อให้เข้าใจลักษณะการกระจายของข้อมูลในชุดข้อมูลนั้น ๆ โดยการวิเคราะห์การแจกแจงข้อมูลจะช่วยให้ผู้ใช้งานสามารถหาข้อมูลสถิติพื้นฐานได้ เช่น ค่าเฉลี่ย ค่าเบี่ยงเบนมาตรฐาน เปอร์เซ็นไทล์ (percentile) และอื่น ๆ เป็นต้น
การแจกแจงข้อมูลมีลักษณะการกระจายของข้อมูลดังนี้
- การกระจายแบบปกติ (Normal Distribution) – เป็นการกระจายของข้อมูลที่มีลักษณะเป็นกระดูกงูเหมือนกันโดยเฉลี่ยและมักจะมีจำนวนมากของข้อมูลอยู่ตรงกลาง (กลางแนวตั้ง) ข้อมูลในการแจกแจงแบบปกติมักมีการกระจายของข้อมูลต่ำ (มีข้อมูลเข้ากลุ่ม) และความสูงสุดของความถี่ของข้อมูลจะอยู่ตรงกลาง
- การกระจายแบบเอียง (Skewed Distribution) – เป็นการกระจายของข้อมูลที่มีแนวโน้มของข้อมูลเอียงไปทางด้านซ้ายหรือด้านขวาของกราฟ โดยค่าเฉลี่ยจะไม่อยู่ตรงกลางของกราฟ การแจกแจงแบบเอียงนั้นมี 2 แบบคือแบบเอียงไปทางด้านซ้าย (Negative Skewness) และแบบเอียงไปทางด้านขวา (Positive Skewness)
- การกระจายแบบแตกต่าง (Uniform Distribution) – เป็นการกระจายของข้อมูลที่มีความน่าจะเป็นที่เท่าๆ กันทุกช่วงของช่วงค่าที่กำหนดไว้ โดยสามารถแสดงด้วยกราฟเส้นตรงที่มีความสูงเท่ากันทุกจุด ซึ่งค่าความน่าจะเป็น (Probability) ในแต่ละช่วงเท่ากัน เช่น ถ้ามีการสุ่มตัวเลขจากช่วง 1-10 แบบสุ่มไม่ซ้ำกัน แล้วแต่ละตัวเลขจะมีความน่าจะเป็นเท่ากันที่จะถูกสุ่มได้ในช่วงนั้นๆ คือ 10%
การแจกแจงข้อมูล (Data Distribution) เป็นหนึ่งในเทคนิคพื้นฐานของ Machine Learning ที่ช่วยให้เราสามารถทำความเข้าใจและวิเคราะห์ข้อมูลได้ดียิ่งขึ้น การแจกแจงข้อมูลนั้นเป็นการอธิบายการกระจายตัวของข้อมูลว่ามีแบบไหนบ้างและมีคุณสมบัติอย่างไร เพื่อช่วยให้เราสามารถเลือกใช้และปรับปรุงโมเดล Machine Learning ได้อย่างถูกต้องและมีประสิทธิภาพสูงสุด
การแจกแจงข้อมูลที่นิยมใช้ใน Machine Learning ได้แก่การใช้งานเมทริกซ์และกราฟสำหรับแสดงการกระจายของข้อมูล เช่น กราฟหลักการกระจายแบบกระจายแตกต่าง (Uniform Distribution) หรือกราฟหลักการกระจายแบบปกติ (Normal Distribution) ซึ่งเป็นกราฟที่นิยมใช้ในการวิเคราะห์ข้อมูลในหลายๆ แนวทางใน Machine Learning
นอกจากนี้เรายังสามารถใช้เทคนิคการคำนวณค่าสถิติพื้นฐาน เช่น mean, median, mode, standard deviation และ percentiles เพื่อวิเคราะห์การแจกแจงข้อมูลได้อย่างละเอียดและมีประสิทธิภาพสูง โดยการใช้เทคนิคเหล่านี้จะช่วยให้เราสามารถปรับปรุงโมเดล Machine Learning ให้มีประสิทธิภาพมากขึ้นโดยการเลือกใช้และปรับพารามิเตอร์ต่างๆ ได้อย่างเหมาะสมกับการกระจายของข้อมูลของเรา
การแจกแจงข้อมูล (Data Distribution) ที่พบได้บ่อยใน Machine Learning คือการกระจายแบบปกติ (Normal Distribution) ซึ่งเป็นการกระจายของข้อมูลที่มีลักษณะเป็นกรวด (bell-shaped) และเป็นการกระจายที่เป็นส่วนใหญ่ในสิ่งแวดล้อมจริง สามารถใช้ฟังก์ชัน scipy.stats.norm ในภาษา Python เพื่อสร้างข้อมูลที่มีการแจกแจงแบบปกติ ตัวอย่างเช่น
import numpy as np
import seaborn as sns
from scipy.stats import norm
# สร้างข้อมูลแบบปกติที่มีค่าเฉลี่ยเท่ากับ 0 และส่วนเบี่ยงเบนมาตรฐานเท่ากับ 1
data = np.random.normal(0, 1, size=1000)
# พล็อตกราฟ histogram ของข้อมูล
sns.histplot(data)
# พล็อตกราฟ distribution plot ของข้อมูล
sns.displot(data, kind="kde", kde_kws={"shade": True})
# พิมพ์ค่าทางสถิติของข้อมูล
print("Mean:", np.mean(data))
print("Standard deviation:", np.std(data))
print("Median:", np.median(data))
print("25th percentile:", np.percentile(data, 25))
print("75th percentile:", np.percentile(data, 75))ผลลัพธ์ที่ได้คือการแสดงข้อมูลแบบปกติที่มีค่าเฉลี่ยเป็น 0 และส่วนเบี่ยงเบนมาตรฐานเป็น 1 พร้อมกับค่าทางสถิติสำคัญอื่น ๆ ของข้อมูล เช่น เมื่อรันโค้ดด้านบน จะได้ผลลัพธ์ประมาณว่า
Mean: -0.004813225107962559
Standard deviation: 1.008738906508032
Median: 0.003926003583550769
25th percentile: -0.6929479975218894
75th percentile: 0.6636967877524477ใน Python มี Library ชื่อว่า NumPy ที่มีฟังก์ชันสำหรับสร้างข้อมูลที่แจกแจงต่างๆ ได้แก่ การแจกแจงแบบเดียวกัน (Uniform Distribution) การแจกแจงแบบปกติ (Normal Distribution) และอื่นๆ นอกจากนี้ยังมี Library อื่นๆ เช่น SciPy และ Matplotlib ที่สามารถใช้สร้างและแสดงผลกราฟของการแจกแจงข้อมูลได้ด้วย
ตัวอย่าง การสร้างข้อมูลแบบแจกแจงแบบเดียวกัน (Uniform Distribution) ด้วย NumPy ดังนี้
import numpy as np
# สร้างข้อมูลแบบแจกแจงแบบเดียวกัน 10 ตัวที่อยู่ในช่วง 0-1
data_uniform = np.random.uniform(0, 1, 10)
print(data_uniform)ผลลัพธ์ที่ได้จะเป็นตัวเลขที่แตกต่างกันแบบสุ่มในช่วง 0-1 ดังนี้
[0.20192101 0.49208214 0.24856264 0.7519365 0.28468051 0.51710089
0.29678832 0.45206496 0.37255773 0.4545764 ]
ตัวอย่าง การแสดงผลกราฟของการแจกแจงแบบเดียวกัน (Uniform Distribution) ด้วย Matplotlib ดังนี้
import numpy as np
import matplotlib.pyplot as plt
# สร้างข้อมูลแบบแจกแจงแบบเดียวกัน 10000 ตัวที่อยู่ในช่วง 0-1
data_uniform = np.random.uniform(0, 1, 10000)
# แสดงกราฟ Histogram
plt.hist(data_uniform, bins=50)
plt.show()
ตัวอย่าง การแจกแจงในลักษณะของความสูงของมนุษย์ โดยมีข้อมูลจำนวน 500 คน และมีค่าเฉลี่ยเท่ากับ 170 ซม. และมีค่าเบี่ยงเบนมาตรฐานเท่ากับ 7.5 ซม. โดยใช้โมดูล NumPy สร้างข้อมูลแบบแจกแจงแบบปกติ (Normal Distribution) จากนั้นแสดงผลลัพธ์ด้วยกราฟ Histogram ด้วยโมดูล Matplotlib
import numpy as np
import matplotlib.pyplot as plt
# สร้างข้อมูลแบบแจกแจงแบบปกติ (Normal Distribution) ของความสูงของมนุษย์ โดยมี mean=170 และ std=7.5
data_normal = np.random.normal(170, 7.5, 500)
# แสดงกราฟ Histogram ของความสูงของมนุษย์
plt.hist(data_normal, bins=20)
plt.title("Distribution of Human Heights")
plt.xlabel("Height (cm)")
plt.ylabel("Frequency")
plt.show()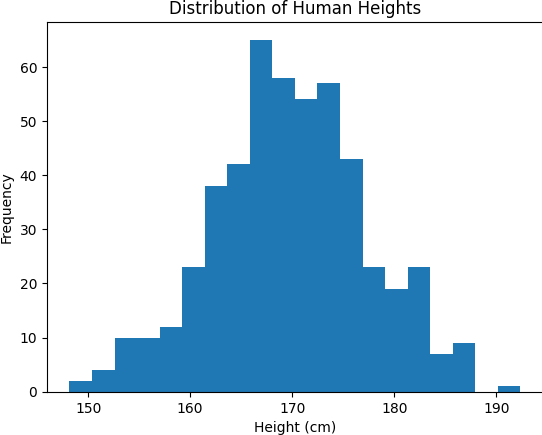
ตัวอย่าง การสร้างข้อมูลแบบแจกแจงแบบปกติ (Normal Distribution) ของน้ำหนักของสุนัขที่มีอายุ 5 ปี โดยใช้ NumPy และ Matplotlib
import numpy as np
import matplotlib.pyplot as plt
# สร้างข้อมูลแบบแจกแจงแบบปกติ 10000 ตัว ที่มี mean = 25 และ std = 3
data_normal = np.random.normal(25, 3, 10000)
# แสดงกราฟ Histogram
plt.hist(data_normal, bins=50)
plt.show()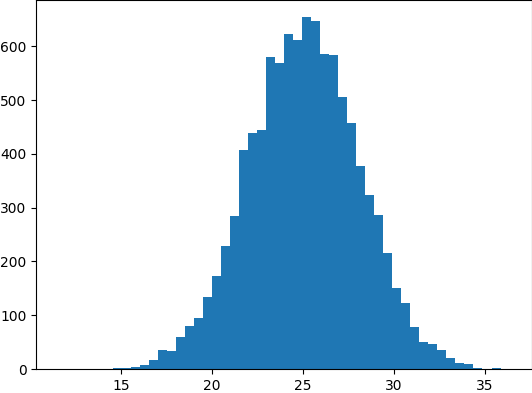
ผลลัพธ์ที่ได้จะเป็นกราฟ Histogram ของการแจกแจงแบบปกติของน้ำหนักของสุนัขที่มีอายุ 5 ปี โดยมี mean เท่ากับ 25 และ standard deviation เท่ากับ 3

