
Convolutional Neural Network (CNN) เป็นแบบจำลองโครงข่ายประสาทเทียมที่ใช้ในการประมวลผลข้อมูลภาพและวิดีโอ โดย CNN มีลักษณะการทำงานแบบชั้นลึก (deep architecture) ซึ่งประกอบด้วยชั้นคอนโวลูชัน (Convolutional Layer) และชั้นพูลลิ่ง (Pooling Layer) เพื่อสกัดลักษณะเด่นของภาพ (features) และลดมิติของภาพลง เพื่อให้ง่ายต่อการประมวลผล ซึ่งจะช่วยลดความซับซ้อนและเพิ่มประสิทธิภาพในการจำแนกภาพ นอกจากนี้ CNN ยังมีการเชื่อมต่อชั้นเป็นลักษณะ forward ซึ่งช่วยให้ CNN สามารถจำแนกภาพอย่างมีประสิทธิภาพได้ โดย CNN ถูกนำไปใช้ในงานต่าง ๆ เช่น การจำแนกภาพ การตรวจจับวัตถุ การตรวจจับใบหน้า การประมวลผลภาพการแยกประเภทของอาหาร การจำแนกเสียง และอื่น ๆ
Convolutional Neural Network (CNN) เป็นโมเดลปัญญาประดิษฐ์ที่ได้รับความนิยมสูงสุดในการแก้ไขปัญหาการประมวลผลภาพและวิดีโอ โดยเฉพาะอย่างยิ่งในงาน Computer Vision โดย CNN นั้นสามารถเรียนรู้และสกัดคุณลักษณะหลายๆ อย่างจากภาพเพื่อแยกแยะว่าภาพนั้นมีสิ่งที่สนใจอยู่แล้วระบุมาเป็น class อะไร เป็นโมเดลประมวลผลภาพ (Image Processing) ซึ่งถูกออกแบบมาเพื่อแก้ไขปัญหาการจำแนกภาพ โดยเฉพาะการจำแนกภาพแบบสองมิติ (2D) เช่น รูปภาพดิจิตัล หรือภาพถ่าย เป็นต้น
โดย CNN มีการนำเข้าภาพเป็นอาร์เรย์หลายมิติ (multi-dimensional array) ซึ่งแต่ละมิติจะแทนความสำคัญของข้อมูลต่าง ๆ ในภาพ เช่น มิติแรกจะแทนความกว้างของภาพ มิติสองจะแทนความสูงของภาพ และมิติสามจะแทนความลึก (depth) ของภาพ โดยแต่ละค่าจะเป็นเลขจำนวนเต็มหรือทศนิยมที่แทนความเข้มของสีในแต่ละพิกเซล (pixel) ของภาพ
CNN จะใช้โมเดลประสาทเทียม (neural network) ที่เรียนรู้รูปแบบ (pattern) ในภาพโดยใช้กระบวนการ Convolution ซึ่งจะสกัดคุณลักษณะของภาพออกมาเป็น feature map และพยายามหาความสัมพันธ์ระหว่าง feature map กับคลาสของภาพ (class) ด้วยการใช้กระบวนการ Pooling และการใช้ Fully-Connected Layer สำหรับการจำแนกภาพ
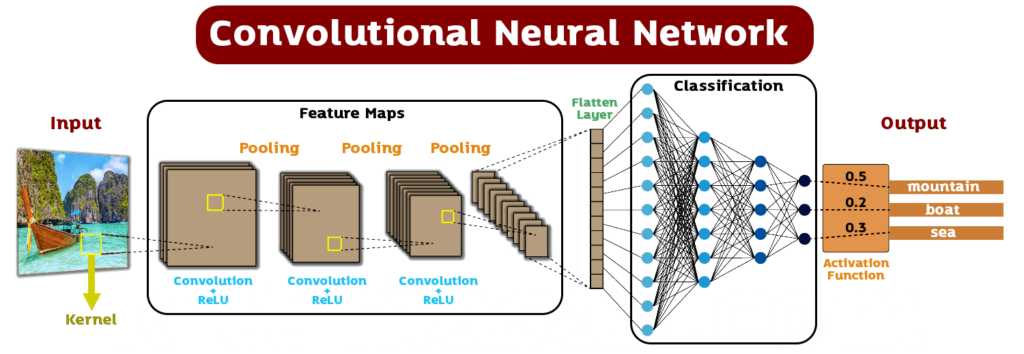
Convolutional Neural Network (CNN) เป็นโมเดลประสาทเทียมที่เหมาะสำหรับงานประมวลผลภาพและวิดีโอ โดย CNN มีการประมวลผลที่เหมือนกับเครื่องประมวลผลของมนุษย์ที่มีการจัดแยกคุณลักษณะเฉพาะของภาพ โดยการทำ Convolution หรือการสกัดลักษณะเฉพาะ (Feature Extraction) จากภาพในขั้นตอนแรก และจากนั้นนำลักษณะเหล่านี้มาใช้ในการจำแนก (Classification) หรือตรวจจับวัตถุ (Object Detection) ในขั้นต่อไป CNN ประกอบด้วยชั้นต่าง ๆ ที่มีหน้าที่ต่างกันดังนี้
-
Input Layer:
ชั้นแรกของโมเดลที่รับข้อมูลเข้ามา เป็นรูปภาพหรือข้อมูลอื่น ๆ โดยมีขนาดและจำนวนช่องคุณลักษณะ (channels) ที่กำหนดไว้ล่วงหน้า -
Convolutional Layer:
ชั้นที่ใช้ในการสกัดลักษณะเฉพาะของภาพ โดยมีการเคลื่อนไหวของ Filter บนภาพเพื่อหาลักษณะเฉพาะของภาพ โดย Filter จะประกอบด้วยเมทริกซ์ขนาดเล็ก ๆ ซึ่งจะเคลื่อนที่เป็นช่วง ๆ บนภาพ และคำนวณผลคูณของแต่ละพิกเซลบนภาพกับเมทริกซ์เพื่อให้ได้ Feature Map ใหม่ ที่สำคัญเป็นชั้นที่มีหน้าที่ใช้ตรวจจับลักษณะ (feature detection) ในรูปแบบของการสกัด (extract) ลักษณะจากรูปภาพด้วยการประมวลผลแบบคอนโวลูชัน (convolution) โดยใช้เครื่องกรอง (filter) หรือเคอร์เนล (kernel) ในการสกัดลักษณะ เมื่อผ่านการสกัดแล้วจะได้ลักษณะเหล่านั้นเป็น feature map -
Activation Layer:
ชั้นที่ใช้ในการแปลงผลลัพธ์จาก Convolutional Layer เป็นค่าที่เป็นไปได้ โดยปกติจะใช้ฟังก์ชัน Activation เช่น ReLU หรือ Sigmoid ที่สำคัญเป็นชั้นที่ใช้ฟังก์ชันเพื่อให้ค่า feature map ที่ได้จาก convolutional layer มีความหมายและเป็นไปตามที่ต้องการ โดยที่ฟังก์ชันที่นิยมใช้มากใน CNN คือ Rectified Linear Unit (ReLU) -
Pooling Layer:
ชั้นที่ใช้ในการลดขนาดของ Feature Map โดยจะเลือกข้อมูลที่สำคัญจาก Feature Map เพื่อลดขนาดของ Feature Map ลงเพื่อลดความซับซ้อนในการคำนวณ และป้องกันการเกิด Overfitting ซึ่งเป็นชั้นที่มีหน้าที่ลดขนาดของ feature map ที่ได้จาก convolutional layer โดยใช้เทคนิค pooling เช่น max pooling หรือ average pooling เพื่อลดการทำงานของโมเดลและเพิ่มประสิทธิภาพในการประมวลผล - Output Layer:
จะประกอบด้วยหนึ่งหรือหลายชั้น Dense Layer ซึ่งสามารถปรับขนาดได้ตามงานที่ต้องการ โดย Output Layer จะใช้ Activation Function ที่เหมาะสมกับงานที่ต้องการ เช่น:- Sigmoid Function: ใช้สำหรับงาน binary classification เพื่อให้ผลลัพธ์ออกมาเป็นค่าความน่าจะเป็นที่เป็น positive class
- Softmax Function: ใช้สำหรับงาน multi-class classification เพื่อให้ผลลัพธ์ออกมาเป็นความน่าจะเป็นของแต่ละ class โดยผลรวมของความน่าจะเป็นจะเท่ากับ 1
- Linear Function: ใช้สำหรับงาน regression เพื่อให้ผลลัพธ์ออกมาเป็นค่าตัวเลขโดยตรงโดยไม่ต้องผ่าน Activation Function ใด ๆ
Convolutional Neural Network (CNN) เป็นโมเดลประสาทเทียมที่ใช้ในการประมวลผลภาพ โดย CNN ใช้กระบวนการคอนโวลูชัน (convolution) เพื่อสกัดลักษณะ (feature) จากภาพ และใช้กระบวนการพูล (pooling) เพื่อลดขนาดของลักษณะนั้นๆ และลดความซับซ้อนของโมเดล จากนั้น CNN จะนำลักษณะที่ได้จากกระบวนการคอนโวลูชันและพูลมาใช้ในการจำแนกภาพ โดยใช้ชั้น fully-connected layer เพื่อทำนายผลลัพธ์ของภาพ
CNN เป็นโมเดลที่เหมาะสำหรับการจำแนกภาพ เนื่องจากสามารถสกัดลักษณะจากภาพได้อย่างมีประสิทธิภาพ และสามารถจำแนกภาพได้ดีเมื่อเปรียบเทียบกับโมเดลประสาทเทียมอื่นๆ นอกจากนี้ CNN ยังมีความสามารถในการจัดการกับภาพที่มีความซับซ้อนสูง และสามารถตรวจจับวัตถุในภาพได้เช่นกัน
นอกจากการประมวลผลภาพแล้ว CNN ยังสามารถนำไปใช้ในงานอื่นๆ เช่น การประมวลผลเสียง (speech recognition) และการประมวลผลข้อความ (text classification) ได้ด้วย Convolutional Neural Network (CNN) เป็นโมเดลประสาทเทียมที่มักถูกนำมาประยุกต์ใช้ในงานด้านการประมวลผลภาพ (image processing) เนื่องจาก CNN มีความสามารถในการค้นหาลักษณะเด่นของภาพ (features) และจำแนกวัตถุ และสิ่งของต่าง ๆ ในภาพได้ดี
การประยุกต์ใช้ CNN ในงานด้านการประมวลผลภาพนั้นมีหลากหลาย เช่น
-
การจำแนกภาพ (image classification) สร้างโมเดลในการจำแนกวัตถุในภาพ(image classification) โดยสามารถจำแนกว่าภาพนั้นๆ เป็นสิ่งของกลุ่มไหน เช่น จำแนกว่าภาพเป็นภาพของแมวหรือหมา การจำแนกวัตถุในภาพ, การตรวจจับใบหน้า, การจำแนกภาพการแยกประเภทอาหาร ฯลฯ
-
การตรวจจับวัตถุ (object detection) สร้างโมเดลในการค้นหาวัตถุในภาพ และป้ายบอกตำแหน่งของวัตถุ ซึ่งเป็นการหาสิ่งของในภาพว่ามีอะไรบ้าง
-
การติดตามวัตถุ (object tracking) ในการติดตามวัตถุในภาพ และทำการปรับปรุงตำแหน่งของวัตถุให้ถูกต้องตามเวลา
-
การเข้ารหัสภาพ (image encoding) เพื่อเข้ารหัสภาพให้อยู่ในรูปแบบที่เหมาะสมสำหรับการแชร์และเก็บรักษาภาพ
-
การจำแนกเสียง (Speech Recognition) สามารถใช้ในการประมวลผลเสียง เช่น การแปลงเสียงพูดเป็นข้อความ การสั่งการด้วยเสียง ฯลฯ
-
การจำแนกข้อความ (Text Classification) สามารถใช้ในการจำแนกข้อความ เช่น การจำแนกข้อความเป็นแบบเรียนรู้เชิงลึก (Deep Learning) หรือจำแนกอย่างต่อเนื่อง (Sequential) เช่น การจำแนกอีเมล์สแปม โดยสามารถรับข้อความเข้ามาแล้วแยกแยะว่าเป็นหมวดหมู่ไหน เช่น ข่าวที่เกี่ยวข้องกับกีฬา หรือข่าวที่เกี่ยวข้องกับการเมือง ซึ่งจะช่วยในการจัดการข้อมูลที่มีปริมาณมากให้มีประสิทธิภาพมากขึ้น
-
การจำแนกวิดีโอ (Video Classification) สามารถใช้ในการจำแนกวิดีโอ เช่น การจำแนกวิดีโอของสัตว์เลี้ยง การแยกประเภทวิดีโอ ฯลฯ
-
การจำแนกความคิด (Sentiment Analysis) สามารถใช้ในการจำแนกความคิดเห็นในสังคมออนไลน์ เช่น การจำแนกความคิดเห็นบนโซเชียลมีเดีย หรือการวิเคราะห์ข้อความและรูปแบบที่เกี่ยวข้องในบทความ
-
การแยกเสียง (audio classification) โดยจะเรียนรู้การจำแนกเสียงต่างๆ เช่น คนพูดเสียงดัง หรือเสียงภาษาต่างประเทศ แล้วนำไปใช้ในการแยกแยะเสียงที่ไม่เหมือนกัน ซึ่งสามารถนำไปใช้ในการพัฒนาโปรแกรม Speech Recognition ได้
การใช้ Python สร้างและใช้งานโมเดล Convolutional Neural Network (CNN) หลังจากได้สร้างและเทรนโมเดล Convolutional Neural Network (CNN) ด้วยภาษา Python แล้ว สามารถนำโมเดลมาใช้งานได้โดยใช้ไลบรารี TensorFlow หรือ Keras ที่มีส่วนช่วยในการเรียกใช้โมเดลได้อย่างง่ายดาย มีขั้นตอนหลัก ๆ ดังนี้
-
เตรียมข้อมูล: นำข้อมูลที่จะนำเข้าโมเดลมาเตรียม โดยส่วนใหญ่จะใช้ไฟล์รูปภาพ (.jpg, .png, .bmp) เป็นต้น และมีขนาดเท่ากันหรือประมาณเท่ากันทุกภาพ โดยใช้เครื่องมือสำหรับการจัดการภาพ เช่น OpenCV หรือ Pillow เพื่อปรับขนาดภาพ และทำการปรับสี (preprocessing) ตามความเหมาะสม
-
สร้างโมเดล: ใช้ไลบรารี Keras หรือ TensorFlow สร้างโมเดล CNN โดยกำหนดชั้นต่าง ๆ ตามที่ต้องการ เช่น Conv2D, MaxPooling2D, Flatten, Dense, Dropout เป็นต้น สามารถปรับแต่งพารามิเตอร์ของแต่ละชั้นได้ตามความต้องการ
-
คอมไพล์และอบหรือ Train โมเดล: ใช้คำสั่ง compile() สำหรับกำหนด optimizer, loss function, และ metrics สำหรับการทดสอบโมเดล และใช้ fit() หรือ fit_generator() สำหรับการฝึกโมเดลโดยให้โมเดลเรียนรู้จากข้อมูล
-
ทดสอบโมเดล: ใช้คำสั่ง evaluate() หรือ predict() สำหรับทดสอบโมเดลกับชุดข้อมูลทดสอบ
-
ปรับแต่งโมเดล: หากต้องการปรับปรุงประสิทธิภาพของโมเดล สามารถปรับแต่งพารามิเตอร์ต่าง ๆ ของโมเดลได้ และทดสอบใหม่เพื่อดูผลลัพธ์
-
โหลดโมเดลที่ได้เทรนแล้ว ใช้ TensorFlow หรือ Keras ในการโหลดไฟล์โมเดลที่ได้เทรนไว้และสามารถนำมาใช้งานได้ โดยจะได้ไฟล์โมเดลแบบ .h5 หรือ .pb ซึ่งเป็นไฟล์ที่เก็บโมเดลพร้อมน้ำหนักและแบบจำลองการเทรน
-
โหลดภาพที่ต้องการจำแนก ใช้ Python และ OpenCV เพื่อโหลดภาพที่ต้องการจำแนก โดยแปลงรูปภาพให้อยู่ในรูปแบบที่โมเดล CNN รองรับ ซึ่งสามารถทำได้โดยการปรับขนาดภาพและทำการแปลงสีภาพ
-
ใช้โมเดลเพื่อจำแนกภาพ นำภาพที่โหลดมาแล้วส่งให้โมเดล CNN ประมวลผล เพื่อทำการจำแนกว่าเป็นภาพประเภทใด โดยผลลัพธ์ที่ได้จะเป็นความน่าจะเป็นของแต่ละประเภท
ตัวอย่าง การใช้งาน Convolutional Neural Network ด้วย TensorFlow
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# สร้างโมเดล CNN
model = keras.Sequential(
[
# ชั้น Input
keras.Input(shape=(28, 28, 1)),
# ชั้น Convolutional
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
# ชั้น Max Pooling
layers.MaxPooling2D(pool_size=(2, 2)),
# ชั้น Convolutional
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
# ชั้น Max Pooling
layers.MaxPooling2D(pool_size=(2, 2)),
# ชั้น Flatten
layers.Flatten(),
# ชั้น Dropout
layers.Dropout(0.5),
# ชั้น Fully Connected
layers.Dense(10, activation="softmax"),
]
)
# แสดงโครงสร้างของโมเดล
model.summary()
# คอมไพล์และเทรนโมเดล
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=128, epochs=15, validation_split=0.1)
# ประเมินประสิทธิภาพของโมเดล
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])จากตัวอย่างนี้ โมเดล CNN ถูกสร้างขึ้นด้วย TensorFlow โดยใช้ Sequential API ที่ใช้สร้างชั้นโมเดลได้อย่างง่ายดาย โดยโมเดลประกอบด้วยชั้น Convolutional 2 ชั้น และ Max Pooling 2 ชั้น ตามลำดับ ก่อนที่จะเข้าสู่ชั้น Flatten เพื่อแปลงภาพเป็นเวกเตอร์ และชั้น Dense 1 ชั้นที่มี 10 โหนดเพื่อระบุผลลัพธ์ในการจำแนก โดยใช้ฟังก์ชัน activation เป็น softmax
การใช้โมเดลประสาทเทียม Convolutional Neural Network ในการจำแนกภาพและประเมินประสิทธิภาพของโมเดล โดยมีขั้นตอนการทำงานดังนี้
- นำเข้าไลบรารี TensorFlow และ Keras พร้อมกับ layers สำหรับสร้างโมเดล CNN
- สร้างโมเดล CNN ด้วย Sequential Model โดยมีชั้น Input ขนาด 28x28x1 และชั้น Convolutional 2 ชั้นที่มี 32 และ 64 filters ตามลำดับ พร้อมกับ Max Pooling หลัง Convolutional แต่ละชั้น และชั้น Dropout สำหรับลดโอกาส Overfitting พร้อมกับชั้น Fully Connected สำหรับการจำแนกเลขอารบิต (0-9) ด้วยฟังก์ชัน activation softmax
- แสดงโครงสร้างของโมเดลด้วยเมธอด summary
- คอมไพล์และเทรนโมเดลด้วย optimizer Adam และ loss function categorical_crossentropy โดยใช้ชุดข้อมูล x_train และ y_train แบบ mini-batch ขนาด 128 และจำนวนรอบการเทรน 15 รอบ พร้อมกับการใช้ validation_split สำหรับแบ่งชุดข้อมูลเพื่อการตรวจสอบประสิทธิภาพของโมเดล
- ประเมินประสิทธิภาพของโมเดลด้วยเมธอด evaluate โดยใช้ชุดข้อมูล x_test และ y_test และแสดงผลลัพธ์เป็นค่า loss และ accuracy ของโมเดล
ตัวอย่าง การใช้โมเดลประสาทเทียม Convolutional Neural Network เพื่อจำแนกภาพตามป้ายชื่อ (image classification) ด้วยข้อมูล MNIST
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# โหลดและเตรียมข้อมูล MNIST
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
x_train = tf.expand_dims(x_train, -1)
x_test = tf.expand_dims(x_test, -1)
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
# สร้างโมเดล CNN
model = keras.Sequential(
[
# ชั้น Input
keras.Input(shape=(28, 28, 1)),
# ชั้น Convolutional
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
# ชั้น Max Pooling
layers.MaxPooling2D(pool_size=(2, 2)),
# ชั้น Convolutional
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
# ชั้น Max Pooling
layers.MaxPooling2D(pool_size=(2, 2)),
# ชั้น Flatten
layers.Flatten(),
# ชั้น Dropout
layers.Dropout(0.5),
# ชั้น Fully Connected
layers.Dense(10, activation="softmax"),
]
)
# แสดงโครงสร้างของโมเดล
model.summary()
# คอมไพล์และเทรนโมเดล
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=128, epochs=15, validation_split=0.1)
# ประเมินประสิทธิภาพของโมเดล
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])จากตัวอย่าง ได้การสร้างและเทรนโมเดลประสาทเทียมแบบ Convolutional Neural Network (CNN) ด้วย TensorFlow ในการจำแนกตัวเลข MNIST ที่เป็นภาพขนาด 28×28 พิกเซล โดยมีขั้นตอนการดำเนินงานดังนี้
- โหลดข้อมูล MNIST จาก Keras และทำการแปลงข้อมูลให้อยู่ในรูปแบบที่เหมาะสมสำหรับการนำเข้าโมเดล CNN
- สร้างโมเดล CNN โดยมีชั้น Convolutional, Max Pooling, Flatten, Dropout, และ Fully Connected ดังนี้
- ชั้น Convolutional แบบ 2D ด้วยขนาด kernel เท่ากับ 3×3 และฟังก์ชัน activation เป็น ReLU โดยมี 32 filters
- ชั้น Max Pooling แบบ 2D ด้วยขนาด pool เท่ากับ 2×2
- ชั้น Convolutional แบบ 2D ด้วยขนาด kernel เท่ากับ 3×3 และฟังก์ชัน activation เป็น ReLU โดยมี 64 filters
- ชั้น Max Pooling แบบ 2D ด้วยขนาด pool เท่ากับ 2×2
- ชั้น Flatten เพื่อแปลง feature maps ให้เป็นเวกเตอร์เพื่อใช้ในชั้น Fully Connected
- ชั้น Dropout เพื่อป้องกัน overfitting โดยกำหนด dropout rate เท่ากับ 0.5
- ชั้น Fully Connected แบบ softmax ที่มี output size เท่ากับ 10 เพื่อใช้ในการจำแนกตัวเลข 0-9
- แสดงโครงสร้างของโมเดล CNN โดยใช้เมธอด summary()
- คอมไพล์และเทรนโมเดลด้วยคำสั่ง compile() และ fit() ตามลำดับ โดยใช้ batch size เท่ากับ 128 และ epochs เท่ากับ 15 พร้อมกำหนด validation split เท่ากับ 0.1
- กำหนด loss function เป็น categorical_crossentropy และ optimizer เป็น adam
- เทรนโมเดลด้วยฟังก์ชัน fit() โดยกำหนดจำนวน batch_size, epochs, และ validation_split
- ประเมินประสิทธิภาพของโมเดล
- ประเมินประสิทธิภาพของโมเดลด้วยฟังก์ชัน evaluate() และแสดงผลลัพธ์ test loss
การจำแนกตัวเลข MNIST ที่มีความแม่นยำ ณ ตอนที่เทรน ประมาณ 99.5% และความแม่นยำในการทดสอบ (test accuracy) ประมาณ 99% ดังนั้นโมเดลที่สร้างขึ้นนี้สามารถจำแนกตัวเลขได้ดีมากๆ โมเดลประกอบไปด้วยชั้นดังนี้
- ชั้น Input: รับ input ขนาด 28×28 พิกเซลและ 1 ช่องสี (grayscale)
- ชั้น Convolutional: มี 32 filters ที่มี kernel size 3×3 และใช้ activation function เป็น ReLU
- ชั้น Max Pooling: ทำ Max Pooling ในขนาด 2×2
- ชั้น Convolutional: มี 64 filters ที่มี kernel size 3×3 และใช้ activation function เป็น ReLU
- ชั้น Max Pooling: ทำ Max Pooling ในขนาด 2×2
- ชั้น Flatten: แปลง output จาก 2 มิติ เป็น 1 มิติ
- ชั้น Dropout: ลดจำนวนโนดในโมเดลเพื่อลดการเรียนรู้ที่เกิดการเรียนรู้แบบเรียนจำ (overfitting)
- ชั้น Fully Connected: มี 10 โนดและใช้ activation function เป็น softmax เพื่อคำนวณความน่าจะเป็นของแต่ละคลาส
โมเดลถูกคอมไพล์ด้วย categorical crossentropy loss function และ Adam optimizer และจำนวนเอพ็อค (epochs) ที่ใช้เทรนคือ 15 และขนาด batch คือ 128 โดยใช้ validation set ที่มีขนาด 10% ของข้อมูลเทรนเพื่อป้องกัน overfitting ในขณะที่โมเดลถูกเทรน
ตัวอย่าง การใช้ Convolutional Neural Network (CNN) ในการจำแนกภาพด้วยความซับซ้อนมากขึ้น โดยใช้ชุดข้อมูล CIFAR-10 ที่ประกอบด้วยภาพขนาด 32×32 พร้อมกับ 10 ชนิดของวัตถุที่แตกต่างกัน โดยประกอบด้วยขั้นตอนต่อไปนี้
- โหลดและเตรียมข้อมูล CIFAR-10
- สร้างโมเดล CNN
- แสดงโครงสร้างของโมเดล
- คอมไพล์และเทรนโมเดล
- ประเมินประสิทธิภาพของโมเดล
ดาวน์โหลด The CIFAR-10 dataset ที่ http://www.cs.toronto.edu/~kriz/cifar.html
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
BATCH_SIZE = 64
# โหลดและเตรียมข้อมูล CIFAR-10
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
# สร้างโมเดล CNN
model = keras.Sequential(
[
# ชั้น Input
keras.Input(shape=(32, 32, 3)),
# ชั้น Convolutional แบบซ้อน
layers.Conv2D(32, kernel_size=(3, 3), padding="same", activation="relu"),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.25),
layers.Conv2D(64, kernel_size=(3, 3), padding="same", activation="relu"),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.25),
layers.Conv2D(128, kernel_size=(3, 3), padding="same", activation="relu"),
layers.Conv2D(128, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.25),
# ชั้น Flatten
layers.Flatten(),
# ชั้น Fully Connected
layers.Dense(512, activation="relu"),
layers.Dropout(0.5),
layers.Dense(10, activation="softmax"),
]
)
# แสดงโครงสร้างของโมเดล
model.summary()
# คอมไพล์และเทรนโมเดล
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
history = model.fit(x_train, y_train, batch_size=64, epochs=15, validation_split=0.1)
# พล็อตกราฟค่าความแม่นยำและค่าความสูญเสียในชุดข้อมูลการตรวจสอบ
plt.plot(history.history["accuracy"], label="accuracy")
plt.plot(history.history["val_accuracy"], label="val_accuracy")
plt.plot(history.history["loss"], label="loss")
plt.plot(history.history["val_loss"], label="val_loss")
plt.xlabel("Epoch")
plt.ylabel("Accuracy/Loss")
plt.legend()
plt.show()
# ประเมินประสิทธิภาพของโมเดล
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])จากตัวอย่าง เป็นโมเดล Convolutional Neural Network (CNN) ที่ใช้กับชุดข้อมูล CIFAR-10 ซึ่งเป็นชุดข้อมูลภาพที่ประกอบด้วยรูปภาพของวัตถุ 10 ประเภทต่างๆ ประกอบด้วยขั้นตอนต่างๆ ดังนี้
- โหลดและเตรียมข้อมูล CIFAR-10 โดยใช้คำสั่ง
keras.datasets.cifar10.load_data()และทำการแบ่งข้อมูลออกเป็นชุดฝึกและชุดทดสอบ โดยข้อมูลฝึกประกอบด้วยภาพและป้ายกำกับของภาพ และข้อมูลทดสอบประกอบด้วยภาพและป้ายกำกับของภาพ - ประกาศโมเดล CNN ที่มีชั้น Convolutional แบบซ้อน 3 ชั้น และชั้น Fully Connected 2 ชั้น รวมถึงชั้น Dropout เพื่อลด overfitting
-
สร้างโมเดล CNN ด้วย
keras.Sequential()โดยมีชั้น Input ที่รับข้อมูลเป็นภาพ และชั้น Convolutional แบบซ้อน ที่ประกอบด้วยชั้น Convolutional ขนาด 32 และ 64 และ 128 พร้อมกับชั้น MaxPooling และ Dropout เพื่อลดการเรียนรู้ซ้ำซ้อนและลดการเรียนรู้จำนวนพารามิเตอร์ ตามลำดับ และมีชั้น Flatten เพื่อแปลงข้อมูลจากรูปแบบ 3 มิติเป็นรูปแบบ 1 มิติ และมีชั้น Fully Connected ที่ประกอบด้วยชั้น Dense 512 และชั้น Dropout เพื่อลดการเรียนรู้ซ้ำซ้อน และมีชั้น Dense 10 ที่ใช้ฟังก์ชั่น activation แบบ softmax เพื่อคำนวณความน่าจะเป็นในการเป็นแต่ละป้ายกำกับ - คอมไพล์และเทรนโมเดล โดยใช้คำสั่ง
model.compile()และmodel.fit()โดยกำหนด loss function เป็น “categorical_crossentropy” และ optimizer เป็น “adam” และกำหนด batch size เป็น 64 และ epochs เป็น 15 และ validation split เป็น 0.1 - พล็อตกราฟค่าความแม่นยำและค่าความสูญเสียในชุดข้อมูลการตรวจสอบด้วย
matplotlibเมื่อโมเดลเทรนเสร็จสิ้นแล้ว จะแสดงผลความแม่นยำและค่าความสูญเสียในชุดข้อมูลการตรวจสอบ ด้วยการพล็อตกราฟจากข้อมูล history ของโมเดล - ประเมินประสิทธิภาพของโมเดลในการทำนายคลาสของรูปภาพในชุดทดสอบ ด้วยคำสั่ง
model.evaluate()
สุดท้ายแสดงผลค่า Test loss และ Test accuracy ของโมเดลในการทำนายชุดข้อมูลทดสอบ

