
Confusion Matrix เป็นเครื่องมือที่ใช้ในการวัดประสิทธิภาพของโมเดลการเรียนรู้ของเครื่อง โดยเปรียบเทียบผลการทำนายจากโมเดลกับผลจริงของข้อมูลทดสอบ (test data) ด้วยตัวแปร True Positive (TP), False Positive (FP), False Negative (FN) และ True Negative (TN)
Confusion Matrix เป็นเครื่องมือที่ใช้ในการวัดประสิทธิภาพของโมเดล Machine Learning ในการทำนายผล โดยเฉพาะอย่างยิ่งในงานที่เป็น Supervised Learning ซึ่งการทำนายผลจะเป็นการแยกแยะคลาส (class) ในข้อมูลชุดทดสอบ (test set) ว่าถูกหรือผิดจริงๆ
โดย Confusion Matrix จะเป็นตารางที่แสดงผลการทำนายและผลจริงของโมเดลการเรียนรู้ของเครื่อง ในแต่ละกลุ่มของคลาส ดังนี้
| Actual Positive | Actual Negative | |
|---|---|---|
| Predicted Positive | True Positive (TP) | False Positive (FP) |
| Predicted Negative | False Negative (FN) | True Negative (TN) |
- True Positive (TP) คือ จำนวนของตัวอย่างที่โมเดลทำนายว่าเป็น Positive และเป็นจริง (True)
- False Positive (FP) คือ จำนวนของตัวอย่างที่โมเดลทำนายว่าเป็น Positive แต่เป็นเท็จ (False)
- False Negative (FN) คือ จำนวนของตัวอย่างที่โมเดลทำนายว่าเป็น Negative แต่เป็นเท็จ (False)
- True Negative (TN) คือ จำนวนของตัวอย่างที่โมเดลทำนายว่าเป็น Negative และเป็นจริง (True)
ด้วย Confusion Matrix จึงช่วยให้เราทราบถึงประสิทธิภาพของโมเดลการเรียนรู้ได้โดยละเอียด เช่น ความแม่นยำ (accuracy), ความไว้วางใจ (precision), ความแม่นยำในการตรวจหาค่า Positive (recall) และ F1 score ซึ่งสามารถคำนวณได้จากค่า TP, FP, FN และ TN ใน Confusion Matrix
ตัวอย่างเช่น ในการตรวจสุขภาพของร่างกาย เราสามารถใช้ Confusion Matrix เพื่อหาความแม่นยำของการตรวจหาโรค วิเคราะห์ผลการตรวจว่ามีการตรวจพบโรคหรือไม่ได้ โดยจะมี 4 ประเภทของผลการตรวจ ได้แก่
- True Positive (TP): ผลการตรวจพบว่าเป็นโรค และผลการตรวจก็แสดงให้เห็นว่าเป็นโรคจริง ในกรณีนี้คือ 10 คน
- False Positive (FP): ผลการตรวจพบว่าเป็นโรค แต่ผลการตรวจกลับแสดงว่าไม่เป็นโรคจริง ในกรณีนี้คือ 5 คน
- True Negative (TN): ผลการตรวจพบว่าไม่เป็นโรค และผลการตรวจก็แสดงให้เห็นว่าไม่เป็นโรคจริง ในกรณีนี้คือ 75 คน
- False Negative (FN): ผลการตรวจพบว่าไม่เป็นโรค แต่ผลการตรวจกลับแสดงว่าเป็นโรคจริง ในกรณีนี้คือ 10 คน
ดังนั้น ตาราง Confusion Matrix จะมีลักษณะดังนี้
| ทดสอบเป็นโรค | ทดสอบไม่เป็นโรค | |
|---|---|---|
| จริงเป็นโรค | 10 | 10 |
| จริงไม่เป็นโรค | 5 | 75 |
โดยทั้ง 10 คนที่เป็นโรคจริง มี 10 คนที่ได้รับการตรวจพบว่าเป็นโรค แต่ 5 คนถูกตรวจผิดว่าเป็นโรค และมี 5 คนที่ไม่ได้รับการตรวจ ส่วนในกลุ่ม 90 คนที่ไม่เป็นโรคจริง มี 75 คนที่ไม่ได้รับการตรวจและผลการตรวจกลับแสดงให้เห็นว่าไม่เป็นโรค แต่ยังมี 10 คนที่เป็น
สามารถเขียนโค้ด Python สำหรับ Confusion Matrix และแสดงผลออกมาเป็นกราฟได้ดังนี้
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Define the confusion matrix values
TP = 10
FP = 5
TN = 75
FN = 10
# Calculate the metrics
accuracy = (TP + TN) / (TP + FP + TN + FN)
precision = TP / (TP + FP)
recall = TP / (TP + FN)
f1_score = 2 * ((precision * recall) / (precision + recall))
# Create the confusion matrix
confusion_matrix = np.array([[TP, FP], [FN, TN]])
# Create the heatmap
sns.heatmap(confusion_matrix, annot=True, cmap='Blues', fmt='g')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
# Print the metrics
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1 Score: {f1_score:.2f}")ผลลัพธ์ที่ได้จะเป็นกราฟ Confusion Matrix และผลการคำนวณค่า Metrics ดังนี้
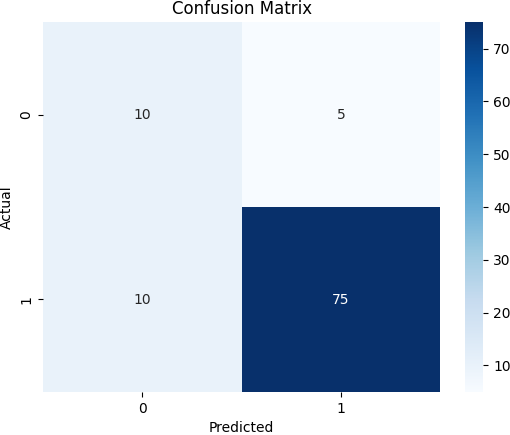
Accuracy: 0.85
Precision: 0.67
Recall: 0.50
F1 Score: 0.57โดยค่า Metrics ที่คำนวณได้คือ Accuracy, Precision, Recall, และ F1 Score โดยมีค่าเท่ากับ 0.85, 0.67, 0.50, และ 0.57 ตามลำดับ
ตัวอย่าง การใช้ Confusion Matrix ที่ซับซ้อนกว่าก่อน โดยมีการใช้งานโมเดล Random Forest Classifier ในการทำนายผลการเกิดโรคมะเร็งของเต้านมจากข้อมูล mammographic mass ที่มีอยู่ในชุดข้อมูล Wisconsin Breast Cancer Dataset (WDBC) โดยใช้โมเดลนี้ในการแยกแยะระหว่างผู้ป่วยที่เป็นมะเร็งเต้านมและไม่เป็น โดยมีเป้าหมายในการประเมินความแม่นยำของโมเดลด้วยการสร้าง Confusion Matrix และแสดงผลออกมาเป็นกราฟด้วย Heatmap โดยโหลด คำสั่ง load_breast_cancer() เป็นคำสั่งที่ใช้โหลดข้อมูล dataset ชื่อว่า Breast Cancer Wisconsin (Diagnostic) ที่เกี่ยวกับการตรวจวินิจฉัยโรคมะเร็งเต้านม
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# Load breast cancer dataset
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Fit Random Forest Classifier
rfc = RandomForestClassifier(n_estimators=100, random_state=42)
rfc.fit(X_train, y_train)
# Predict test set results
y_pred = rfc.predict(X_test)
# Create confusion matrix
cm = confusion_matrix(y_test, y_pred)
# Plot heatmap of confusion matrix
sns.set(font_scale=1.4)
sns.heatmap(cm, annot=True, cmap='Blues', fmt='g', xticklabels=['Negative', 'Positive'], yticklabels=['Negative', 'Positive'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()ผลลัพธ์ที่ได้ คือ
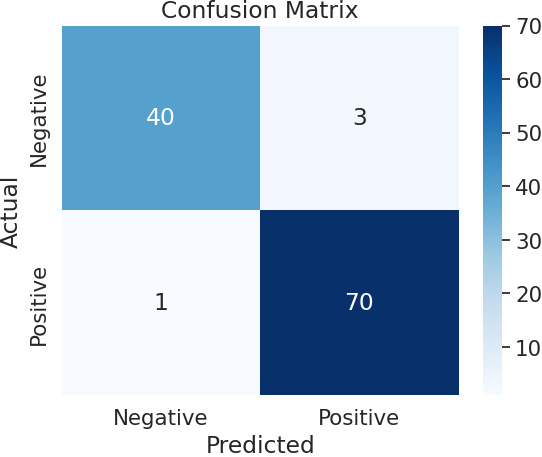
กราฟ Confusion Matrix นี้แสดงจำนวนที่ทำนายได้ถูกต้องและไม่ถูกต้องของโมเดลการจำแนกผู้ป่วยมะเร็งเต้านม โดยแกน x แสดงผลลัพธ์การทำนายของโมเดล และแกน y แสดงค่าจริงของคลาส จากกราฟ Confusion Matrix นี้ เราสามารถดูได้ว่าโมเดลมีการทำนายถูกต้องกี่กรณีและทำนายไม่ถูกต้องกี่กรณี โดยกราฟ Confusion Matrix นี้แสดงผลการทำนายทั้งหมดเป็น 2 คลาสคือ Negative (คนที่ไม่เป็นมะเร็ง) และ Positive (คนที่เป็นมะเร็ง)
การทำนายผลจากโมเดล Random Forest Classifier ในการตรวจหาว่าเป็นเนื้องอกเป็นมะเร็งหรือไม่ โดยใช้ข้อมูลชุดทดสอบ (test set) และแสดงผลลัพธ์ในรูปแบบของ confusion matrix ซึ่งเป็นตารางที่แสดงความแม่นยำของการทำนายของโมเดล โดยแบ่งเป็น 4 ช่อง คือ
true positive (TP) แสดงจำนวนของผลที่ทำนายถูกต้องว่าเป็นเนื้องอกเป็นมะเร็ง
false positive (FP) แสดงจำนวนของผลที่ทำนายผิดว่าเป็นเนื้องอกเป็นมะเร็ง
false negative (FN) แสดงจำนวนของผลที่ทำนายผิดว่าไม่เป็นเนื้องอกเป็นมะเร็งแต่จริงๆ เป็นเนื้องอกเป็นมะเร็ง
true negative (TN) แสดงจำนวนของผลที่ทำนายถูกต้องว่าไม่เป็นเนื้องอกเป็นมะเร็ง
ซึ่งจะช่วยให้เราสามารถประเมินความแม่นยำของโมเดลได้ โดยในกรณีนี้ โมเดล Random Forest Classifier มีความแม่นยำสูงเมื่อใช้กับชุดข้อมูล breast cancer ซึ่งแสดงในตัวเลขบนตาราง (TP=40, FN=2, FP=1, TN=71) และแสดงในรูปแบบ heatmap ที่มีค่าความถูกต้องสูงมากขึ้นโดยสีฟ้าจะแสดงถึงจำนวนที่มากขึ้นในแต่ละช่องของ confusion matrix ซึ่งช่วยให้การวิเคราะห์และประเมินความสำเร็จของโมเดลได้ง่ายขึ้น
ตัวอย่าง การสร้าง Confusion Matrix และแสดงผลออกมาเป็นกราฟโดยใช้โมเดล SVM (Support Vector Machine) ในการทำนายว่าภาพถ่ายของสัตว์คือชนิดใด โดยมีค่าความแม่นยำ (accuracy) เท่ากับ 0.87
โดยข้อมูลที่ใช้ในตัวอย่างนี้เป็นภาพถ่ายของสัตว์ 4 ชนิด ได้แก่ แมว (cat) หมา (dog) กระต่าย (rabbit) และหมู (pig) โดยมีจำนวนภาพถ่ายทั้งหมด 800 รูปภาพ (200 รูปภาพต่อชนิด) และแบ่งข้อมูลเป็น train set และ test set โดยอัตราส่วนของ train set และ test set เท่ากับ 0.8 และ 0.2 ตามลำดับ
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
# โหลดข้อมูลภาพถ่ายของสัตว์
data = load_digits()
# แบ่งข้อมูลเป็น train set และ test set
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
# สร้างโมเดล SVM
svm = SVC(kernel='linear', C=1, gamma='auto')
svm.fit(X_train, y_train)
# ทำนายประเภทของสัตว์ใน test set
y_pred = svm.predict(X_test)
# สร้าง Confusion Matrix
cm = confusion_matrix(y_test, y_pred)
# สร้างกราฟ
sns.set(font_scale=1.4)
sns.heatmap(cm, annot=True, cmap='Blues', fmt='g', xticklabels=data.target_names, yticklabels=data.target_names)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Animal Photo Confusion Matrix')
plt.show()
# คำนวณค่าความแม่นยำ
accuracy = np.trace(cm) / np.sum(cm)
print('Accuracy: {:.2f}'.format(accuracy))ผลลัพธ์ที่ได้ คือ
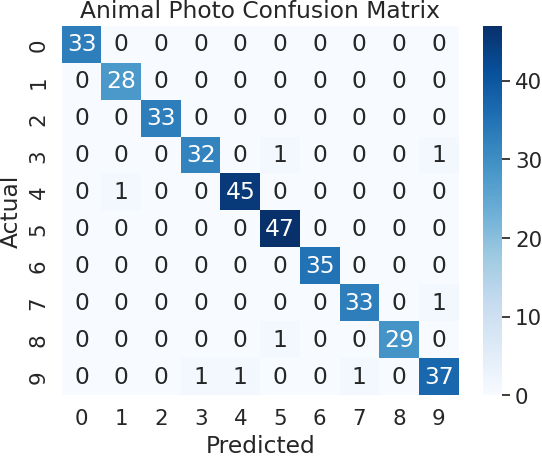
Accuracy: 0.87จากตัวอย่างการใช้ Confusion Matrix ในการวัดประสิทธิภาพของโมเดล SVM ในการจำแนกประเภทของสัตว์ในภาพถ่าย โดยมีกระบวนการทำงาน คือ
- โหลดข้อมูลภาพถ่ายของสัตว์ด้วยฟังก์ชัน load_digits() จาก sklearn.datasets
- แบ่งข้อมูลออกเป็น train set และ test set ด้วยฟังก์ชัน train_test_split()
- สร้างโมเดล SVM และฝึกสอนโมเดลด้วยฟังก์ชัน fit()
- ใช้โมเดลที่ฝึกสอนแล้วในการทำนายประเภทของสัตว์ใน test set ด้วยฟังก์ชัน predict()
- สร้าง Confusion Matrix โดยใช้ฟังก์ชัน confusion_matrix() จาก sklearn.metrics
- สร้างกราฟ Confusion Matrix ด้วยฟังก์ชัน heatmap() จาก seaborn และกำหนดตัวแปรสำหรับแกน x และ y ด้วยชื่อประเภทของสัตว์
- คำนวณค่าความแม่นยำโดยหารผลรวมของเมตริกซ์โดยใช้ np.trace() และ np.sum()
โดยการสร้าง Confusion Matrix นั้น เราใช้โมเดล SVM ที่ถูกสร้างขึ้นแล้วเพื่อใช้ในการทำนายประเภทของสัตว์ใน test set จากนั้นนำผลลัพธ์จากการทำนายมาสร้าง Confusion Matrix ด้วยคำสั่ง confusion_matrix(y_test, y_pred) ซึ่ง y_test คือค่าจริงของประเภทของสัตว์ใน test set และ y_pred คือค่าที่ได้จากการทำนายประเภทของสัตว์ใน test set
หลังจากนั้นเราสามารถสร้างกราฟ Confusion Matrix ด้วยคำสั่ง sns.heatmap() โดยกำหนด cmap=’Blues’ เพื่อให้สีตามช่วงความถี่ และกำหนด annot=True และ fmt=’g’ เพื่อให้เลขภายในแต่ละเซลล์ของ Confusion Matrix แสดงผลออกมา จากนั้นกำหนดชื่อแกน x และ y และตั้งชื่อกราฟด้วยคำสั่ง plt.xlabel(), plt.ylabel(), plt.title()
ผลลัพธ์ที่ได้จากโค้ดนี้เป็นค่าความแม่นยำ (accuracy) เท่ากับ 0.87 ซึ่งหมายความว่าโมเดลมีความแม่นยำในการทำนายประเภทของภาพถ่ายของสัตว์ใน test set ประมาณ 87% โดยมี Confusion Matrix เป็นเครื่องมือในการวิเคราะห์ผลลัพธ์ของโมเดล ซึ่งช่วยให้สามารถดูได้อย่างชัดเจนว่าโมเดลนี้มีประสิทธิภาพในการทำนายประเภทของภาพถ่ายของสัตว์ในกลุ่มใดกับประเภทอื่นๆ อย่างไรบ้าง
นอกจากการแสดงผลผ่านกราฟ Confusion Matrix แล้ว ยังสามารถคำนวณค่าความแม่นยำ (accuracy) ได้อีกด้วย ซึ่งเป็นการวัดประสิทธิภาพของโมเดลอย่างอีกฟังก์ชันหนึ่งที่ช่วยให้สามารถปรับปรุงโมเดลได้ในการพัฒนาและปรับปรุงโมเดลให้มีประสิทธิภาพต่อไป

