
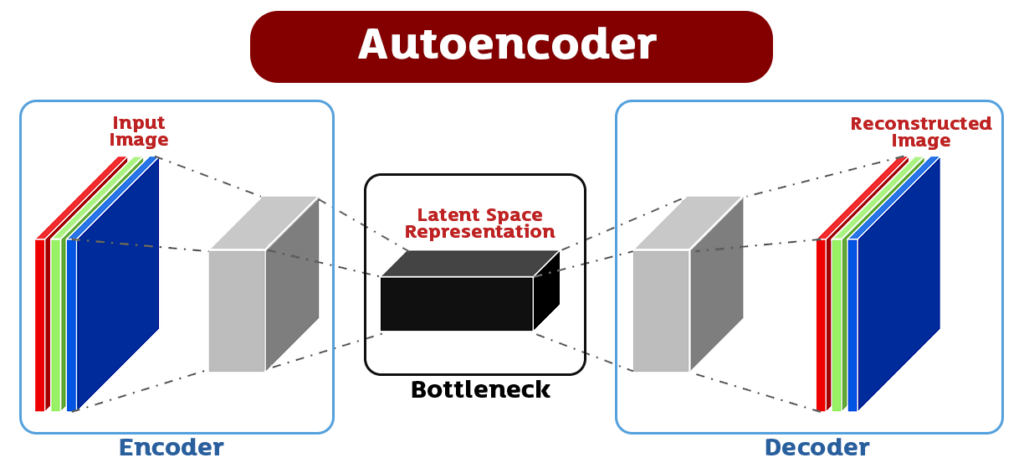
Autoencoder เป็นโมเดล Deep Learning ที่ใช้สำหรับการลดขนาดของข้อมูล (dimensionality reduction) โดยที่ข้อมูลเข้าเป็น input และออกมาเป็น output โดยมีตัวกลาง (hidden layer) ซึ่งมีจำนวน node น้อยกว่า input layer และ output layer โดยปกติแล้วจะใช้โมเดล Neural Network ในการสร้าง Autoencoder โดยมี 2 ส่วนหลัก คือ Encoder และ Decoder ซึ่งแต่ละส่วนจะมีหน้าที่ดังนี้
- Encoder
รับ input และทำการแปลงข้อมูลเป็น feature vector ที่มี dimension น้อยลงเช่น จากภาพขนาด 28×28 pixels ให้เป็น vector ขนาด 128, 64 หรือ 32 ใน hidden layer - Decoder
รับ feature vector และทำการแปลงเป็น output ที่มี dimension เดียวกับ input ซึ่งในที่นี้จะเป็นภาพขนาดเดียวกับภาพ input
การใช้ Autoencoder นั้นมีประโยชน์หลายด้านเช่น การลดจำนวน feature เพื่อลดการ overfitting ในโมเดล Neural Network, การลดรูปภาพ (image compression) หรือการหา feature ที่สำคัญในข้อมูลอื่นๆ เช่น การหา feature ที่สำคัญในเสียง (voice feature) หรือความหมายของคำ (word embeddings)
Autoencoder เป็นเครื่องมือทางคณิตศาสตร์และการเรียนรู้เชิงลึก (Deep Learning) ที่มีการพัฒนาขึ้นมาเพื่อเพิ่มประสิทธิภาพในการเรียนรู้และการประมวลผลของระบบ โดย Autoencoder จะเป็นโมเดล Neural Network ที่มีความซับซ้อนต่ำและถูกออกแบบมาให้สามารถเรียนรู้และสร้างเส้นทางการเข้ารหัส (Encoding) และการถอดรหัส (Decoding) ของข้อมูลเข้าสู่พื้นที่สูงมิติ (High-dimensional space) ให้มีคุณภาพและความแม่นยำมากขึ้น
หลักการของ Autoencoder คือ การสร้างโมเดล Neural Network ที่ประกอบด้วยชั้น Hidden Layer ที่มีจำนวนมาก โดยโมเดลจะถูกฝึกให้เรียนรู้จากข้อมูล Input ที่ใส่เข้าไป โดยจะมีการเรียนรู้การเข้ารหัส (Encoding) ของข้อมูล และเมื่อได้ข้อมูลที่ถูกเข้ารหัสแล้ว โมเดลจะนำข้อมูลที่ถูกเข้ารหัสไปสร้างเป็นรูปแบบใหม่ที่คล้ายคลึงกับข้อมูล Input เดิม ซึ่งจะเรียกว่าการถอดรหัส (Decoding) ข้อมูล
การใช้ Autoencoder ใน Deep Learning มีหลายวิธีการ อย่างไรก็ตาม หลักการหลักของการใช้ Autoencoder คือการใช้เครื่องมือนี้เพื่อสร้างเส้นทางการเข้ารหัสและถอดรหัสของข้อมูลที่จะนำไปใช้ในงานอื่นๆ เช่น การเพิ่มประสิทธิภาพในการจัดกลุ่มข้อมูล (Clustering) การตรวจจับความผิดปกติ (Anomaly Detection) เป็นต้น
Autoencoder เป็นแบบจำลองโครงข่ายประสาทเทียม (neural network) ที่มีการฝึกเรียนแบบไม่มีผู้ติดตั้ง (unsupervised learning) ที่สามารถใช้สร้างโมเดลในการเรียนรู้และสกัดคุณลักษณะ (feature extraction) ของข้อมูลเข้าสู่ระบบโดยไม่ต้องมีการระบุคำตอบ (label) ของข้อมูล โดยโมเดล Autoencoder มักถูกนำมาใช้ในงานประมวลผลภาพ (image processing) และการประมวลผลข้อมูลตัวเลข (numerical data processing)
โดยปกติแล้ว Autoencoder ประกอบด้วยสองส่วนหลัก คือส่วนของ Encoder และส่วนของ Decoder โดย Encoder จะทำหน้าที่แปลงข้อมูลเข้าสู่รูปแบบที่เหมาะสมสำหรับการสกัดคุณลักษณะของข้อมูล และกลับทำงานในส่วนของ Decoder เพื่อสร้างข้อมูลเดิมกลับมาจากคุณลักษณะที่ได้สกัดไว้
การฝึก Autoencoder จะมีการสร้างค่าสัญญาณข้อมูลเข้าสู่ระบบโดยใช้ส่วน Encoder เพื่อสกัดคุณลักษณะ (feature) ของข้อมูล และกลับด้วยส่วน Decoder เพื่อสร้างค่าสัญญาณใหม่ที่สามารถใช้แทนค่าสัญญาณเดิมได้โดยมีความคล้ายคลึงในระดับที่ต้องการ การฝึกโมเดล Autoencoder นั้นเป็นการปรับพารามิเตอร์ของโมเดลโดยให้ค่าความคล้ายคลึงของค่าสัญญาณและค่าสัญญาณเดิมมีค่าสูงสุดโดยใช้วิธีการลดค่าสูญเสีย (loss function)
การใช้ Autoencoder ใน Deep Learning มีเทคนิคหลายรูปแบบ เพื่อสร้างโมเดลที่มีประสิทธิภาพในการเรียนรู้และสกัดคุณลักษณะของข้อมูล
เทคนิคสำคัญที่นิยมใช้ในการสร้าง Autoencoder ได้แก่
-
Convolutional Autoencoder (CAE)
เป็น Autoencoder ที่ใช้ชั้น Convolutions แทนชั้น Fully Connected Layers เพื่อให้สามารถประมวลผลข้อมูลที่เป็นภาพได้มากขึ้น ด้วยการใช้ Convolutions จะช่วยสกัดคุณลักษณะของรูปภาพออกมาได้ดีกว่า และยังช่วยลดจำนวนพารามิเตอร์ของโมเดลลงได้อีกด้วย -
Denoising Autoencoder (DAE)
เป็น Autoencoder ที่ถูกออกแบบมาเพื่อเรียนรู้คุณลักษณะของข้อมูลที่ถูกเสียหาย โดยการสร้างข้อมูลสัญญาณบันทึกเสียงหรือภาพที่เสียหายจากข้อมูลต้นฉบับ และนำสัญญาณที่เสียหายมาเป็น input ให้กับ DAE เพื่อเรียนรู้วิธีการกู้คืนข้อมูลต้นฉบับ ซึ่งจะช่วยป้องกันการเกิด Overfitting ในกรณีที่ข้อมูลต้นฉบับเป็น noisy หรืออาจจะมี outlier อยู่บ้าง -
Variational Autoencoder (VAE)
เป็น Autoencoder ที่มีการเพิ่ม Gaussian Noise เข้าไปในข้อมูลก่อนที่จะป้อนให้กับ Encoder และนำข้อมูลที่ผ่านการสกัดคุณลักษณะจาก Encoder มาสร้างเป็นเวกเตอร์ใน latent space โดยการสร้างเป็น Gaussian Distribution ซึ่งจะช่วยให้โมเดลสามารถสร้างข้อมูลใหม่ได้
นอกจากการใช้ Autoencoder เพื่อปรับปรุงคุณภาพของภาพแล้ว ยังสามารถนำ Autoencoder ไปใช้ในการแก้ปัญหาในด้านอื่น ๆ ของการประมวลผลภาพด้วย เช่นการลดมิติของข้อมูล (dimensionality reduction) หรือการหาคำอธิบายของภาพ (image captioning)

Convolution นำเข้าระหว่าง 4x4x1 และ ตัวกรอง Convolutional Autoencoder (CAE) 3x3x1
ผลลัพธ์ที่ได้ คือ Activation Map 2x2x1
การลดมิติของข้อมูลด้วย Autoencoder จะช่วยให้สามารถลดขนาดของข้อมูลและควบคุมความเชื่อมโยงของตัวแปรได้ โดยโมเดลจะเรียนรู้วิธีการบีบอัดข้อมูลไปยังแกนต่าง ๆ ที่สำคัญที่สุดเพื่อสร้างตัวแทน (representation) ของข้อมูลที่ยังคงความสำคัญอยู่ ซึ่งตัวแทนนี้จะช่วยให้ง่ายต่อการนำไปใช้งานและประมวลผลต่อไป
สำหรับการใช้ Autoencoder ในการค้นหาคำอธิบายของภาพ โมเดลจะเรียนรู้วิธีการแปลงภาพเป็นตัวเลข และสร้างตัวแทนของภาพเหล่านี้ โดยการใช้ encoder ที่เรียนรู้วิธีการสกัดลักษณะของภาพ และ decoder ที่ใช้สร้างภาพขึ้นมาจากตัวแทนของภาพที่ถูกเรียนรู้ โดยตัวแทนนี้จะถูกนำไปใช้ในการสร้างคำอธิบายของภาพ โดยปกติแล้วจะนำไปใช้งานร่วมกับโมเดล RNN (Recurrent Neural Network) หรือ LSTM (Long Short-Term Memory) เพื่อให้โมเดลสามารถเข้าใจและสร้างคำอธิบายได้ดีขึ้น
การสร้าง Autoencoder แบ่งได้เป็นขั้นตอนดังนี้
- กำหนดโครงสร้างของ Autoencoder
- กำหนดจำนวน layer และจำนวนโหนดของแต่ละ layer
- กำหนดฟังก์ชัน activation สำหรับแต่ละ layer
- กำหนดฟังก์ชัน loss สำหรับการปรับปรุงโมเดล
- รับข้อมูลที่ต้องการสร้างโมเดล Autoencoder
- กำหนดขนาดของรูปภาพหรือข้อมูลที่ต้องการให้ Autoencoder จำแนก
- โหลดข้อมูลเข้าสู่ระบบ
- สร้างโมเดล Autoencoder
- สร้างโมเดลให้สอดคล้องกับโครงสร้างที่กำหนดไว้
- ฝึกโมเดล Autoencoder
- นำข้อมูลเข้าสู่โมเดล Autoencoder เพื่อทำการฝึกโมเดล
- ปรับปรุงพารามิเตอร์ของโมเดลเพื่อทำให้ค่า loss ลดลง
- ใช้โมเดล Autoencoder
- นำข้อมูลที่ต้องการให้ Autoencoder จำแนกผ่านโมเดล
- ใช้ผลลัพธ์จากโมเดล Autoencoder ในการฝึกโมเดลอื่นหรือการจำแนกข้อมูลด้วยแบบ supervised learning
รูปแบบของการใช้ Autoencoder ใน Deep Learning มีดังนี้
-
การใช้สกัดลักษณะ (Feature Extraction)
โมเดล Autoencoder สามารถใช้ในการสกัดลักษณะของข้อมูลจากภาพ หรือชุดข้อมูลต่างๆ โดยมีการฝึกโมเดลโดยไม่มีการตั้งเป้าหมายในการทำนาย โดยประโยชน์ที่ได้รับจากการสกัดลักษณะดังกล่าวนั้น เป็นการลดขนาดของข้อมูลโดยที่ยังคงคุณลักษณะหลักของข้อมูลไว้ ซึ่งจะช่วยให้การประมวลผลข้อมูลเป็นไปได้เร็วขึ้น และลดการถ่ายทอดของข้อมูลซึ่งส่งผลกระทบต่อประสิทธิภาพการเรียนรู้ของโมเดลในภายหลัง -
การใช้ปรับปรุงคุณภาพของภาพ (Image Enhancement)
โมเดล Autoencoder สามารถใช้ในการปรับปรุงคุณภาพของภาพได้ โดยการฝึกโมเดลโดยใช้ภาพต้นฉบับเป็นข้อมูล input และภาพที่ถูกปรับปรุงคุณภาพเป็นข้อมูล output โดยจะใช้ฟังก์ชันของ Autoencoder ในการเรียนรู้ลักษณะของภาพ และปรับปรุงคุณภาพของภาพได้อย่างมีประสิทธิภาพ -
การใช้ควบคุมความเร็วในการเรียนรู้ (Learning Rate Control)
การใช้ Autoencoder สามารถช่วยในการควบคุมความเร็วในการเรียนรู้ของโมเดลได้ โดยการใช้ Autoencoder เป็นตัวกำหนดค่าเริ่มต้น
การนำไปใช้ประโยชน์ในการประมวลผลภาพ และมีการนำไปใช้งานในหลายแบบอย่าง เช่น
-
การลดมิติ (Dimensionality Reduction)
Autoencoder สามารถใช้ในการลดมิติของข้อมูลได้ เช่น หากมีข้อมูลหลายตัวที่มี dimension สูงอย่างเช่นภาพ 28×28 pixels ความสูงและความกว้าง ต่อจากนั้น Autoencoder จะช่วยประมวลผลเพื่อลด dimension ลงเหลือเพียงไม่กี่ตัว เพื่อให้ง่ายต่อการประมวลผลในอนาคต -
การสร้างภาพ (Image Generation)
Autoencoder สามารถใช้ในการสร้างภาพที่มีความคล้ายคลึงกับภาพต้นฉบับได้ โดยให้ Encoder และ Decoder ทำงานร่วมกัน เพื่อให้ Decoder สามารถสร้างภาพจาก feature vectors ที่ถูกสร้างขึ้นโดย Encoder ได้ สิ่งที่สำคัญ Autoencoder สามารถใช้สำหรับการสร้างภาพ (Image Generation) ได้ โดยการสร้าง feature จากข้อมูลต้นแบบและสร้างภาพใหม่ -
การกำจัด Noise ของข้อมูล (Noise Reduction)
Autoencoder สามารถใช้สำหรับการกำจัด noise จากภาพได้ เช่น ภาพที่ถูกเพิ่ม noise เป็นเสียงเงียบ ๆ จะสามารถนำมาใช้ในการฟื้นฟูภาพได้ โดยให้ Encoder สร้าง feature vectors จากภาพเสียงและ Decoder จะนำ feature vectors ดังกล่าวมาสร้างภาพที่มีความคล้ายคลึงกับภาพต้นฉบับโดยทำการกำจัด noise ออก -
การตรวจสอบความคลาดเคลื่อน (Anomaly Detection)
Autoencoder สามารถใช้ในการตรวจจับคลาดเคลื่อนหรือสิ่งที่ผิดปกติได้ เช่น หากมีภาพที่เป็นคลาสเดียวกัน -
การการบีบอัดข้อมูล (Data Compression)
Autoencoder สามารถใช้สำหรับการการบีบอัดข้อมูลได้ โดยใช้การลดขนาดของข้อมูลให้มีขนาดเล็กลง เช่น รูปภาพที่เป็นขนาดใหญ่โดยมีพื้นที่ที่ไม่มีความสำคัญในการแสดงผล เราสามารถใช้ Autoencoder เพื่อลดขนาดของรูปภาพได้ โดยที่ไม่สูญเสียข้อมูลสำคัญ -
การค้นหาความคล้ายคลึง (Similarity Search)
Autoencoder สามารถใช้สำหรับการค้นหาความคล้ายคลึง (Similarity Search) ได้ โดยใช้ feature ที่ถูกสกัดมาจากข้อมูล เพื่อค้นหาข้อมูลที่มีลักษณะคล้ายกันหรือคล้ายคู่กัน -
การจัดกลุ่ม (Clustering)
Autoencoder สามารถใช้สำหรับการจัดกลุ่มข้อมูล (Clustering) ได้ Autoencoder จะถูกใช้ในการเพิ่มความลึก (Deepen) ของโมเดล แต่ในกรณีนี้ Autoencoder จะถูกใช้ในการสกัด feature ที่มีความหมายออกมาจากข้อมูล แล้วจัดกลุ่มข้อมูลด้วย feature เหล่านี้ ซึ่งจะช่วยให้การจัดกลุ่มเป็นไปได้อย่างมีประสิทธิภาพขึ้น
ตัวอย่าง การใช้ Autoencoder ใน Deep Learning ประยุกต์ใช้ การลดมิติ (Dimensionality Reduction) ด้วยชุดข้อมูล MNIST
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, Dense
# โหลดชุดข้อมูล MNIST
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# ปรับขนาดของรูปภาพให้อยู่ในช่วง [0, 1]
X_train = X_train.astype('float32') / 255.
X_test = X_test.astype('float32') / 255.
# แปลงรูปภาพขนาด 28x28 เป็น vector ขนาด 784
X_train = X_train.reshape((len(X_train), np.prod(X_train.shape[1:])))
X_test = X_test.reshape((len(X_test), np.prod(X_test.shape[1:])))
# สร้างโมเดล Autoencoder
input_img = Input(shape=(784,))
encoded = Dense(32, activation='relu')(input_img) # ลดมิติในชั้น encoded
decoded = Dense(784, activation='sigmoid')(encoded) # ส่งคืนเป็น vector ขนาดเดิม
autoencoder = Model(input_img, decoded)
encoder = Model(input_img, encoded)
# คอมไพล์โมเดล
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# ฝึกโมเดล
autoencoder.fit(X_train, X_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(X_test, X_test))
# ใช้โมเดล Autoencoder ที่ฝึกมาในการแปลงรูปภาพเป็น vector ขนาด 32
encoded_imgs = encoder.predict(X_test)
# แสดงรูปภาพต้นฉบับและรูปภาพที่ถูกแปลงเป็น vector ขนาด 32 จากโมเดล Autoencoder
n = 10 # จำนวนรูปภาพที่จะแสดงผล
plt.figure(figsize=(20, 4))
for i in range(n):
# แสดงรูปภาพต้นฉบับ
ax = plt.subplot(2, n, i + 1)
plt.imshow(X_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# แสดงรูปภาพที่ถูกแปลงเป็น vector ขนาด 32 จากโมเดล Autoencoder
ax = plt.subplot(2, n, i + n + 1)
plt.imshow(encoded_imgs[i].reshape(8, 4)) # แสดงเป็นรูปภาพขนาด 8x4
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()จากตัวอย่างการใช้ Autoencoder ในการลดมิติของภาพและแสดงรูปภาพต้นฉบับและรูปภาพที่ถูกแปลงเป็น vector ขนาด 32 จากโมเดล Autoencoder ในรูปแบบของภาพดิจิตอลขนาด 28×28 ของชุดข้อมูล MNIST โดยโค้ดประกอบด้วยหลายส่วนหลักๆ ดังนี้:
-
โหลดชุดข้อมูล MNIST และปรับขนาดของรูปภาพให้อยู่ในช่วง [0, 1] โดยใช้คำสั่ง
mnist.load_data()เพื่อโหลดชุดข้อมูล MNIST และใช้astype()และ/เพื่อแปลงชนิดของข้อมูลเป็นfloat32และปรับขนาดของข้อมูลให้อยู่ในช่วง [0, 1] -
แปลงรูปภาพขนาด 28×28 เป็น vector ขนาด 784 โดยใช้
reshape()เพื่อเปลี่ยนขนาดของข้อมูล -
สร้างโมเดล Autoencoder โดยใช้
Input()เพื่อสร้างชั้นข้อมูลเข้ารหัส (encoder) ที่มีขนาดเป็น 32 และชั้นข้อมูลถอดรหัส (decoder) ที่มีขนาดเป็น 784 -
คอมไพล์โมเดล Autoencoder โดยใช้
compile()เพื่อกำหนด optimizer และฟังก์ชัน loss -
ฝึกโมเดล Autoencoder โดยใช้
fit()เพื่อฝึกโมเดล -
ใช้โมเดล Autoencoder ที่ฝึกมาในการแปลงรูปภาพเป็น vector ขนาด 32 โดยใช้
encoder.predict() -
แสดงรูปภาพต้นฉบับและรูปภาพที่ถูกแปลงเป็น vector ขนาด 32 จากโมเดล Autoencoder โดยใช้
imshow()
การสร้างโมเดล Autoencoder และนำมาใช้กับชุดข้อมูล MNIST เพื่อทำการลดมิติของข้อมูลรูปภาพและแสดงผลลัพธ์ที่ได้ โดย Autoencoder ที่สร้างขึ้นนี้มีชั้นระหว่าง (intermediate layer) ที่มีจำนวน unit เป็น 32 จะทำหน้าที่ในการลดมิติของข้อมูลรูปภาพเหล่านั้น และชั้นสุดท้ายของ Autoencoder จะส่งคืนข้อมูลออกมาในรูปแบบของ vector ขนาดเดิม ซึ่งจะใช้ในการเปรียบเทียบกับรูปภาพต้นฉบับ
หลังจากที่ Autoencoder ได้รับการฝึกด้วยชุดข้อมูล X_train แล้ว ผลลัพธ์ที่ได้จะถูกนำไปใช้ในการแปลงรูปภาพในชุดทดสอบ (X_test) เป็น vector ขนาด 32 โดยใช้โมเดล Encoder ที่ได้จากการสร้าง Autoencoder นี้ ซึ่งผลลัพธ์จะถูกเก็บไว้ในตัวแปร encoded_imgs
สุดท้าย โค้ดด้านบนจะแสดงผลลัพธ์ในรูปแบบของภาพ โดยแสดงรูปภาพต้นฉบับและรูปภาพที่ถูกแปลงเป็น vector ขนาด 32 โดยใช้โมเดล Autoencoder ที่ฝึกมา โดยรูปภาพที่ถูกแสดงผลจะเป็นรูปภาพที่อยู่ในชุดข้อมูล X_test โดยจะแสดงผลในลักษณะของแถวทั้ง 2 แถว โดยแถวแรกจะเป็นรูปภาพต้นฉบับ และแถวที่สองจะเป็นรูปภาพที่ถูกแปลงเป็น vector ขนาด 32
ตัวอย่าง การใช้ Autoencoder ในการสร้างภาพ (Image Generation) โดยใช้ชุดข้อมูล CIFAR-10
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import cifar10
from keras.models import Model
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
# โหลดชุดข้อมูล CIFAR-10
(X_train, _), (X_test, _) = cifar10.load_data()
# ปรับขนาดของรูปภาพให้อยู่ในช่วง [0, 1]
X_train = X_train.astype('float32') / 255.
X_test = X_test.astype('float32') / 255.
# สร้างโมเดล Autoencoder
input_img = Input(shape=(32, 32, 3))
x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(16, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
encoded = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(3, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_img, decoded)
# คอมไพล์โมเดล
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# ฝึกโมเดล
autoencoder.fit(X_train, X_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(X_test, X_test))
# ใช้โมเดล Autoencoder ที่ฝึกมาในการสร้างภาพ
decoded_imgs = autoencoder.predict(X_test)
# แสดงรูปภาพต้นฉบับและรูปภาพที่ถูกสร้างขึ้นโดยโมเดล Autoencoder
n = 10 # จำนวนรูปภาพที่จะแสดงผล
plt.figure(figsize=(20, 4))
for i in range(n):
# แสดงรูปภาพต้นฉบับ
ax = plt.subplot(2, n, i + 1)
plt.imshow(X_test[i])
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# แสดงรูปภาพที่ถูกสร้าง
ax = plt.subplot(2, n, i + n + 1)
plt.imshow(decoded_imgs[i])
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()จากตัวอย่าง การสร้างโมเดล Autoencoder และใช้งานกับชุดข้อมูล CIFAR-10 เพื่อสร้างภาพใหม่จากรูปภาพต้นฉบับ โดยใช้ Keras เป็นฟรีและเปิดเผยโค้ดแพ็กเกจ deep learning framework ที่ใช้งานได้ง่าย
โมเดล Autoencoder ที่สร้างขึ้นใช้ Convolutional Neural Network (CNN) เพื่อเข้ารหัส (encode) และถอดรหัส (decode) ภาพ โดยมีหน้าที่หลักคือการลดขนาดของภาพเพื่อเก็บข้อมูลที่สำคัญเฉพาะอย่างเดียว เมื่อถอดรหัสภาพกลับมาจะได้ภาพใหม่ที่มีความคล้ายคลึงกับภาพต้นฉบับ แต่อาจมีการละเว้นรายละเอียดที่ไม่สำคัญ
โค้ด Python นี้ทำการปรับขนาดของรูปภาพให้อยู่ในช่วง [0, 1] และสร้างโมเดล Autoencoder ที่มี 4 layers โดยมี 2 convolutional layers และ 2 max pooling layers ในการเข้ารหัส และ 2 convolutional layers และ 2 upsampling layers ในการถอดรหัส โดยใช้ activation function เป็น relu ในชั้นที่เป็น convolutional layer และใช้ sigmoid ในชั้นที่เป็น output layer โดยเป็นแบบ binary_crossentropy loss function และใช้ optimizer ชื่อ adam
หลังจากนั้นโมเดลถูกฝึกด้วยชุดข้อมูล X_train และ X_test ในการสร้างภาพใหม่จากโมเดล Autoencoder โดยใช้ฟังก์ชัน predict และนำรูปภาพต้นฉบับและภาพที่ถูกสร้างขึ้นโดยโมเดล Autoencoder มาแสดงผลด้วย Matplotlib
การสร้างและใช้งานโมเดล Autoencoder ด้วยภาษา Python และไลบรารี Keras โดยการฝึกโมเดล Autoencoder ด้วยชุดข้อมูล CIFAR-10 และสร้างภาพที่ถูกสร้างขึ้นโดยโมเดล Autoencoder จากชุดข้อมูลนี้ เป้าหมายของ Autoencoder คือการเรียนรู้แทนการสกัดลักษณะ (feature extraction) จากรูปภาพและซ่อมแซม (image reconstruction) ภาพต้นฉบับจากลักษณะที่ได้รับการเรียนรู้
โดยโค้ดนี้มีขั้นตอนการทำงานดังนี้
- โหลดชุดข้อมูล CIFAR-10 จากไลบรารี Keras และทำการปรับขนาดของรูปภาพให้อยู่ในช่วง [0, 1]
- สร้างโมเดล Autoencoder โดยใช้ชั้น Conv2D, MaxPooling2D, และ UpSampling2D เพื่อสกัดลักษณะจากรูปภาพและซ่อมแซมภาพต้นฉบับจากลักษณะที่ได้รับการเรียนรู้
- คอมไพล์โมเดล Autoencoder โดยใช้ optimizer เป็น ‘adam’ และ loss เป็น ‘binary_crossentropy’
- ฝึกโมเดล Autoencoder ด้วยชุดข้อมูลฝึกและชุดข้อมูลทดสอบ
- ใช้โมเดล Autoencoder ที่ฝึกมาในการสร้างภาพ
- แสดงรูปภาพต้นฉบับและรูปภาพที่ถูกสร้างขึ้นโดยโมเดล Autoencoder
ตัวอย่าง การใช้ Autoencoder ในการกำจัด Noise จากภาพดิจิทัล โดยใช้ชุดข้อมูล MNIST และ Noise ด้วย Gaussian noise ที่มีค่าเฉลี่ยเป็น 0 และส่วนเบี่ยงเบนมาตรฐานเป็น 0.5 โดยภายในโมเดลจะประกอบไปด้วยชั้น Convolutional และ Pooling ที่ใช้ในการเข้ารหัส (encoder) และถอดรหัส (decoder) ของภาพ โดยใช้ฟังก์ชัน activation เป็น ReLU ในชั้นเชิงคณิตศาสตร์และฟังก์ชัน activation เป็น Sigmoid ในชั้นสุดท้ายของโมเดล เพื่อใช้ในการสร้างภาพที่ไม่มี Noise
# นำเข้าไลบรารีที่ใช้
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
from tensorflow.keras.preprocessing.image import load_img, img_to_array
from tensorflow.keras.preprocessing.image import array_to_img
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.models import load_model
import os
# กำหนดค่า noise factor
noise_factor = 0.5
# โหลด dataset
(x_train, _), (x_test, _) = mnist.load_data()
# ทำการ normalize ค่าพิกเซล
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
# เพิ่ม noise แบบสุ่มให้กับรูปภาพ
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
# จำกัดค่าให้อยู่ในช่วง 0-1
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
# กำหนดรูปแบบ input
input_shape = (28, 28, 1)
# กำหนดโครงสร้างของโมเดล
input_img = Input(shape=input_shape)
# encoder layers
x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
# decoder layers
x = UpSampling2D((2, 2))(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
# คอมไพล์โมเดล
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# สรุปโมเดล
autoencoder.summary()
# ฝึกโมเดล
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=5)
mc = ModelCheckpoint('best_model.h5', monitor='val_loss', mode='min', save_best_only=True)
history = autoencoder.fit(x_train_noisy, x_train, epochs=50, batch_size=128, shuffle=True, validation_data=(x_test_noisy, x_test), callbacks=[es, mc])
# ประเมินผลโมเดล test set
best_model = load_model('best_model.h5')
test_loss = best_model.evaluate(x_test_noisy, x_test)
print('Test loss:', test_loss)
# ทำนายภาพ denoised
decoded_imgs = best_model.predict(x_test_noisy)
# พล็อตตัวอย่างบางส่วนของภาพต้นฉบับ สำหรับภาพ noisy และ denoised
n = 10 # number of images to show
plt.figure(figsize=(20, 4))
for i in range(n):
# ภาพต้นฉบับ
ax = plt.subplot(3, n, i+1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# ภาพ noisy
ax = plt.subplot(3, n, i+1+n)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# ภาพ denoised
ax = plt.subplot(3, n, i+1+2*n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()จากตัวอย่าง เป็นโมเดล autoencoder ที่ใช้กับชุดข้อมูล MNIST เพื่อกำจัด Noise ออกจากรูปภาพ โดยมีขั้นตอนดังนี้
- Import libraries เช่น numpy, matplotlib, keras, และ os
- กำหนด noise factor สำหรับการสร้างรูปภาพที่มีเสียงรบกวน
- Load ชุดข้อมูล MNIST และทำการ normalize ข้อมูล pixel values
- เพิ่มเสียงรบกวนในรูปภาพโดยการใช้ numpy.random.normal และ noise factor ที่กำหนดไว้
- Clip ค่า pixel values ในช่วง 0-1 range
- กำหนด input shape ของโมเดล
- กำหนดโครงสร้างของโมเดล autoencoder โดยใช้ Conv2D, MaxPooling2D, UpSampling2D และ activation function ที่กำหนดไว้
- Compile โมเดลด้วย optimizer เป็น adam และ loss เป็น binary_crossentropy
- Train โมเดลด้วย fit และกำหนด callbacks เพื่อหยุดการ train และบันทึก best model ที่มีค่า loss ต่ำที่สุด
- Evaluate โมเดลด้วย test set และแสดง test loss
- Predict รูปภาพที่ได้รับเสียงรบกวนแล้วและแสดงรูปภาพเปรียบเทียบระหว่าง original, noisy, และ denoised images ที่ได้จาก best model ที่สร้างขึ้นและบันทึกไว้ในไฟล์ best_model.h5
โมเดล Autoencoder ที่ใช้เพื่อกำจัด Noise จากภาพดิจิทัลของชุดข้อมูล MNIST โดยโมเดลนี้ประกอบด้วย layer ของ Convolutional Neural Network (CNN) ที่ใช้ในการ encode และ decode ภาพ โดยโมเดลจะถูก train โดยใช้ชุดข้อมูลที่เป็นภาพ MNIST ที่มีการเพิ่มเสียงรบกวนเข้าไป และหลังจาก train เสร็จสิ้นโมเดลจะถูกใช้ในการทำนายภาพของชุดข้อมูลทดสอบ (x_test_noisy) เพื่อหาค่าของสูญเสีย (loss) และใช้ในการแสดงผลภาพของภาพต้นฉบับ (original), ภาพที่มีเสียงรบกวน (noisy) และภาพที่ถูกลบเสียงรบกวนแล้ว (denoised) จำนวน n รูปภาพ โดยใช้ matplotlib.pyplot เพื่อแสดงผลภาพ ผลลัพธ์ที่แสดงจะเป็นรูปภาพที่มีแถบสีเทา (grayscale) ขนาด 28×28 พร้อมกับค่า loss ที่ได้จากการทำนายชุดข้อมูลทดสอบและแสดงผลภาพดังกล่าวผ่านหน้าต่างกราฟิก (GUI) ที่แสดงผลภาพ 10 รูปภาพ ตามที่กำหนดไว้ในตัวแปร n
ตัวอย่าง การใช้ Autoencoder ของ Deep Learning โดยประยุกต์ใช้ในการตรวจสอบความคลาดเคลื่อน (Anomaly Detection)
import libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
# สร้างข้อมูลแบบสุ่ม
np.random.seed(42)
n_samples = 1000
n_features = 5
data = pd.DataFrame(np.random.rand(n_samples, n_features), columns=[f"Feature {i+1}" for i in range(n_features)])
# ทำการ normalize ข้อมูล
data = (data - np.min(data)) / (np.max(data) - np.min(data))
# แบ่งข้อมูลเป็นชุด train และ test
train_data = data.sample(frac=0.8, random_state=42)
test_data = data.drop(train_data.index)
กำหนดโมเดล Autoencoder
input_dim = train_data.shape[1]
encoding_dim = 3
input_layer = Input(shape=(input_dim,))
encoder = Dense(encoding_dim, activation='relu')(input_layer)
decoder = Dense(input_dim, activation='sigmoid')(encoder)
autoencoder = Model(input_layer, decoder)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
# ทำการ train โมเดล
history = autoencoder.fit(train_data, train_data,
epochs=50, batch_size=64,
shuffle=True, validation_data=(test_data, test_data))
# ทำการทำนายผลบนข้อมูลทดสอบ
test_predictions = autoencoder.predict(test_data)
# คำนวณค่า reconstruction error
mse = np.mean(np.power(test_data - test_predictions, 2), axis=1)
# กำหนด threshold สำหรับการตรวจสอบความผิดปกติ
threshold = np.mean(mse) + 2*np.std(mse)
# แยกข้อมูลที่มีความผิดปกติ
anomalies = test_data.loc[mse > threshold]
# พล็อตกราฟ reconstruction error
plt.hist(mse, bins=50)
plt.axvline(threshold, color='red', linestyle='dashed', linewidth=2)
plt.xlabel("Reconstruction Error")
plt.ylabel("Frequency")
plt.show()
# พล็อตกราฟข้อมูลที่มีความผิดปกติ
for col in anomalies.columns:
plt.figure()
plt.scatter(test_data.index, test_data[col], label='Normal')
plt.scatter(anomalies.index, anomalies[col], color='red', label='Anomaly')
plt.legend()
plt.title(col)
plt.show()โดยขั้นตอนการประมวลผลมีดังนี้
- Import libraries เพื่อใช้ในการทำงานต่าง ๆ รวมถึง tensorflow, pandas, matplotlib เป็นต้น
- โหลดชุดข้อมูลเข้าสู่ DataFrame และทำการ Normalize ข้อมูล
- แบ่งชุดข้อมูลออกเป็นชุด Train และ Test
- กำหนดโครงสร้าง Autoencoder ด้วยการใช้ Layer แบบ Dense
- ทำการ Train Autoencoder ด้วยชุดข้อมูล Train
- นำชุดข้อมูล Test มาทำนายผลจาก Autoencoder และคำนวณ Reconstruction Error
การสร้างโมเดล Autoencoder และนำไปใช้ตรวจจับความผิดปกติในข้อมูล โดยการทำงานของโมเดลนี้คือใช้ข้อมูลในการฝึกเรียนเพื่อเรียนรู้รูปแบบของข้อมูล และจากนั้นใช้โมเดลเพื่อทำนายข้อมูลทดสอบ โดยการคำนวณค่า reconstruction error หากค่า reconstruction error เกิน threshold ที่กำหนดไว้ จะถือว่าเป็นความผิดปกติ โค้ดจะแยกข้อมูลที่มีความผิดปกติออกมาและพล็อตกราฟข้อมูลที่มีความผิดปกติเพื่อให้ง่ายต่อการวิเคราะห์
โดย Autoencoder เป็นโมเดลประเภท Deep Learning ที่มักนำมาใช้ในงานการประมวลผลภาพ โดยโมเดลนี้จะมีสองส่วนหลัก คือ Encoder และ Decoder โดย Encoder จะใช้ในการทำ feature extraction หรือแปลงข้อมูลให้อยู่ในรูปแบบที่เหมาะสมกับงานที่ต้องการ และ Decoder จะใช้ในการแปลงข้อมูลที่ถูก encode ไว้กลับมาเป็นรูปแบบเดิม
ในการตรวจสอบความผิดปกติของข้อมูล โมเดล Autoencoder จะใช้ Encoder ในการสกัดลักษณะที่สำคัญของข้อมูล และนำไปสร้าง representation ใหม่เพื่อใช้ในการสร้างข้อมูลใหม่ที่คล้ายคลึงกับข้อมูลเดิม จากนั้นใช้ Decoder ในการแปลง representation กลับเป็นข้อมูลเดิม และนำไปเปรียบเทียบกับข้อมูลจริงเพื่อคำนวณค่า reconstruction error ซึ่งถูกใช้ในการตรวจสอบความผิดปกติของข้อมูล โดยสามารถกำหนด threshold สำหรับการตรวจสอบความผิดปกติได้
ตัวอย่าง การใช้ Autoencoder ในการบีบอัดข้อมูล (Data Compression)
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
# สร้างข้อมูลแบบสุ่ม
np.random.seed(42)
n_samples = 1000
n_features = 10
data = np.random.rand(n_samples, n_features)
# ทำการ normalize ข้อมูล
data = (data - np.min(data)) / (np.max(data) - np.min(data))
# แบ่งข้อมูลเป็นชุด train และ test
train_data = data[:800, :]
test_data = data[800:, :]
# กำหนดโมเดล Autoencoder
input_dim = train_data.shape[1]
encoding_dim = 3
input_layer = Input(shape=(input_dim,))
encoder = Dense(encoding_dim, activation='relu')(input_layer)
decoder = Dense(input_dim, activation='sigmoid')(encoder)
autoencoder = Model(input_layer, decoder)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
# ทำการ train โมเดล
history = autoencoder.fit(train_data, train_data,
epochs=50, batch_size=64,
shuffle=True, validation_data=(test_data, test_data))
# ทำการทำนายผลบนข้อมูลทดสอบ
test_predictions = autoencoder.predict(test_data)
# พล็อตกราฟแสดงผลการบีบอัดข้อมูล
plt.scatter(test_data[:, 0], test_data[:, 1], label='Original')
plt.scatter(test_predictions[:, 0], test_predictions[:, 1], label='Compressed')
plt.legend()
plt.show()จากตัวอย่าง จะสร้างข้อมูลแบบสุ่มด้วย NumPy และทำการ normalize ข้อมูลก่อนที่จะแบ่งเป็นชุด train และ test ด้วย NumPy array slicing และกำหนดโมเดล Autoencoder ที่มี 1 input layer, 1 hidden layer ที่ใช้ activation function เป็น ReLU และ 1 output layer ที่ใช้ activation function เป็น sigmoid สำหรับการบีบอัดข้อมูล เมื่อโมเดลถูก train เสร็จแล้ว จะทำการทำนายผลบนชุดข้อมูลทดสอบ และพล็อตกราฟแสดงผลการบีบอัดข้อมูล โดยเปรียบเทียบข้อมูลเดิมกับข้อมูลที่ผ่านการบีบอัดแล้วในกราฟเดียวกัน
การใช้ Autoencoder ของ Deep Learning ในการบีบอัดข้อมูล โดยประยุกต์ใช้กับข้อมูลแบบสุ่ม ทำการสร้างข้อมูลแบบสุ่มขนาด 1000 x 10 และทำการ normalize ข้อมูล เพื่อให้ค่าข้อมูลอยู่ในช่วง 0 ถึง 1
จากนั้นแบ่งข้อมูลเป็นชุด train และ test โดยใช้ train_data 800 ตัวและ test_data 200 ตัว
กำหนดโมเดล Autoencoder โดยใช้ input layer ขนาด input_dim, encoder ที่มี node 3 โดยใช้ activation function ชนิด ReLU และ decoder ที่มี node 10 โดยใช้ activation function ชนิด Sigmoid
ทำการ compile โมเดล Autoencoder โดยใช้ optimizer ชนิด adam และ loss function ชนิด mean squared error
ทำการ train โมเดล Autoencoder ด้วยชุด train_data โดยทำ 50 epochs และ batch size 64
ทำการทำนายผลบนชุด test_data และพล็อตกราฟแสดงผลการบีบอัดข้อมูล โดยแสดงผลข้อมูลแบบเดิม (Original) และผลการบีบอัด (Compressed) ขนาด 2 มิติในแผนภูมิกระจาย (Scatter plot)
ตัวอย่าง การใช้ Autoencoder ในการค้นหาความคล้ายคลึง (Similarity Search) จากข้อมูล MNIST โดยใช้ Nearest Neighbors Algorithm
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from sklearn.neighbors import NearestNeighbors
# โหลดข้อมูล MNIST
(x_train, _), (x_test, _) = mnist.load_data()
# ทำการ normalize ข้อมูล
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
# แปลงข้อมูลเป็น vector 1 มิติ
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# กำหนดโมเดล Autoencoder
input_dim = x_train.shape[1]
encoding_dim = 32
input_layer = Input(shape=(input_dim,))
encoder = Dense(encoding_dim, activation='relu')(input_layer)
decoder = Dense(input_dim, activation='sigmoid')(encoder)
autoencoder = Model(input_layer, decoder)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
# ทำการ train โมเดล
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
# สร้างโมเดล Encoder เพื่อใช้ในการค้นหาความคล้ายคลึง
encoder_model = Model(inputs=input_layer, outputs=encoder)
# ทำการ encode ข้อมูลในชุดทดสอบ
encoded_test_data = encoder_model.predict(x_test)
# ค้นหาความคล้ายคลึงด้วยวิธี Nearest Neighbors
nbrs = NearestNeighbors(n_neighbors=10, algorithm='ball_tree').fit(encoded_test_data)
distances, indices = nbrs.kneighbors(encoded_test_data)
# พล็อตรูปภาพต้นฉบับและรูปภาพที่ค้นหามาใกล้เคียงที่สุด
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# รูปภาพต้นฉบับ
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# รูปภาพที่ค้นหามาใกล้เคียงที่สุด
for j in range(1, 10):
ax = plt.subplot(2, n, i + n*j + 1)
plt.imshow(x_test[indices[i][j]].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()จากตัวอย่าง การสร้างและทดสอบโมเดล Autoencoder และใช้ Nearest Neighbors เพื่อค้นหาภาพที่มีความคล้ายคลึงกับภาพต้นฉบับในชุดทดสอบของ MNIST dataset ดังนั้นผลลัพธ์ที่คาดหวังจากโค้ดนี้คือการแสดงภาพต้นฉบับและภาพที่ค้นหามาใกล้เคียงที่สุดจาก Nearest Neighbors
โดยในการสร้างโมเดล Autoencoder นั้น ได้ทำการ normalize ข้อมูลด้วยการแปลงเป็นค่าตัวเลขจาก 0-1 และแปลงข้อมูลเป็น vector 1 มิติ โดยใช้ชั้น Dense 2 ชั้น ซึ่งชั้นแรกมีจำนวน node เท่ากับ 32 และใช้ activation function เป็น relu ส่วนชั้นที่สองมีจำนวน node เท่ากับจำนวน feature ของข้อมูลและใช้ activation function เป็น sigmoid โดยโมเดล Autoencoder นี้จะใช้ optimizer เป็น adam และ loss function เป็น mean squared error
ในขั้นตอนการทดสอบโมเดล Autoencoder นี้ ได้ทำการใช้โมเดล Encoder เพื่อ encode ข้อมูลในชุดทดสอบ จากนั้นใช้ Nearest Neighbors เพื่อค้นหาภาพที่มีความคล้ายคลึงกับภาพต้นฉบับ โดยกำหนดให้เลือกภาพที่มีความคล้ายคลึงกับภาพต้นฉบับ 10 รูป และใช้ algorithm เป็น ball_tree
ผลลัพธ์ที่คาดหวังจากโค้ดนี้คือการแสดงภาพต้นฉบับและภาพที่ค้นหามาใกล้เคียงที่สุดจาก Nearest Neighbors โดยแต่ละคู่จะถูกแสดงในแถวเดียวกัน การแสดงรูปภาพต้นฉบับ และรูปภาพที่ค้นหามาใกล้เคียงที่สุดสำหรับแต่ละรูป โดยใช้โมเดล Autoencoder เพื่อทำการ encode และ decode ข้อมูล และใช้ Nearest Neighbors เพื่อค้นหาข้อมูลที่มีความคล้ายคลึงกันมากที่สุดโดยใช้โมเดล Encoder ที่สร้างขึ้นมาจากโมเดล Autoencoder นี้
ตัวอย่าง การใช้ Autoencoder ในการจัดกลุ่มข้อมูลด้วยการทำ Clustering ด้วยวิธี K-Means
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
# โหลดข้อมูล MNIST
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# ทำการ normalize ข้อมูล
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
# แปลงข้อมูลเป็น vector 1 มิติ
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# กำหนดโมเดล Autoencoder
input_dim = x_train.shape[1]
encoding_dim = 32
input_layer = Input(shape=(input_dim,))
encoder = Dense(encoding_dim, activation='relu')(input_layer)
decoder = Dense(input_dim, activation='sigmoid')(encoder)
autoencoder = Model(input_layer, decoder)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
# ทำการ train โมเดล
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
# สร้างโมเดล Encoder เพื่อใช้ในการ encoding ข้อมูล
encoder_model = Model(inputs=input_layer, outputs=encoder)
# ทำการ encode ข้อมูลทั้งหมด
encoded_data = encoder_model.predict(np.concatenate((x_train, x_test)))
# ทำการ clustering ด้วยวิธี K-Means
kmeans = KMeans(n_clusters=10, random_state=0).fit(encoded_data)
# พล็อตรูปภาพตัวอย่างจากทุกกลุ่ม
fig, axs = plt.subplots(10, 10, figsize=(10, 10))
for i in range(10):
for j in range(10):
# เลือกข้อมูลในกลุ่มที่ i และ j
group = np.where(kmeans.labels_ == i)[0]
sample = group[j]
# แสดงรูปภาพตัวอย่าง
axs[i, j].imshow(x_test[sample].reshape(28, 28))
axs[i, j].axis('off')
axs[i, j].set_title(f'Group {i}')
plt.show()จากตัวอย่าง จะโหลดข้อมูล MNIST และทำการ normalize ข้อมูลก่อนจะใช้ Autoencoder ในการ encode ข้อมูล และทำการ train โมเดล Autoencoder ด้วยข้อมูลในชุด Train
การใช้ Autoencoder ในการแปลงข้อมูล MNIST ที่มีรูปภาพขนาด 28×28 เป็น vector 1 มิติ (1D vector) แล้วนำไปทำการ clustering ด้วยวิธี K-Means ในการแบ่งกลุ่มข้อมูลเป็น 10 กลุ่ม จากนั้นแสดงผลรูปภาพตัวอย่างจากทุกกลุ่ม
ผลลัพธ์ที่ได้คือ รูปภาพตัวอย่างจากทุกกลุ่มที่ถูกแบ่งออกมา โดยแต่ละกลุ่มมีลักษณะเด่นของตัวเลขที่ต่างกัน เช่นกลุ่มที่ 0 จะมีลักษณะของตัวเลข 0 และ 6 ในขณะที่กลุ่มที่ 1 จะมีลักษณะของตัวเลข 1 และ 7 โดยสามารถสรุปได้ว่าการใช้ Autoencoder และ Clustering เป็นเครื่องมือที่มีประสิทธิภาพในการจัดกลุ่มข้อมูล และสามารถนำไปใช้กับงานที่ต้องการแบ่งกลุ่มข้อมูลต่าง ๆ ได้เช่นกัน

